Application Layer Plugins
Der nscale Server Application Layer bietet die Möglichkeit, sogenannte Plugins (oft auch als Hooks bezeichnet) zur Laufzeit des Servers zu laden. Plugins sind Erweiterungen/Klassen, die die Standardfunktionalität des Servers auf verschiedenste Art und Weise beeinflussen. So können mit Plugins beispielsweise die Standardimplementierungen der Serverschnittstelle erweitert oder vollständig überschrieben werden. Externe Services können eingebunden werden. Dieses geht bis hin zur sehr feingranularen Anpassung der abgesetzten SQL-Statements des Servers.
Dieses Dokument behandelt nicht die einzelnen Möglichkeiten der Plugin-Entwicklung (diese werden nur kurz im nächsten Kapitel angerissen). Es geht vielmehr darum, auf Stolpersteine hinzuweisen und auf Punkte, die bei der Plugin-Entwicklung unbedingt zu beachten sind.
1. Plugin Typen
Im nscale Server Application Layer gibt es verschiedene Stellen, an denen Plugins zum Einsatz kommen können. In erster Linie werden Plugins durch das Konfigurationsobjekt PluginsSetting konfiguriert. Darüber hinaus gibt es aber weitere Möglichkeiten, Plugins zu definieren, z.B. gibt es im Bereich Workflow drei Arten von Workflow-Handlern, im Einzelnen DecisionHandler, AssignmentHandler und ActionHandler. Weitere Möglichkeiten sind Plugins zur Anpassung von automatisch verschickten Emails oder zur Anpassung des Deckblatts bei einem Ordner-Export. In diesem Dokument werden überwiegend Plugins aus dem PluginsSetting betrachtet.
Im PluginsSetting werden 17 verschiedene Typen von Plugins angeboten, wobei der ServiceInvocationHook noch den Untertyp OutOfContextServiceInvocationHook besitzt. Von einigen Plugin Typen können beliebig viele Instanzen existieren, während einige nur höchstens einmal instanziiert werden können (Singletons). Jedes Plugin referenziert eine Java-Klasse, die ein Handler-Interface implementieren muss, das zu dem jeweiligen Plugin Typ passt.
Die unten stehende Tabelle gibt einen Überblick über die neun am häufigsten benutzten Plugin Typen des PluginsSettings
und die über die jeweiligen Handler-Interfaces zur Verfügung
gestellten Methoden, die vom nscale Server Application Layer an geeigneten Stellen aufgerufen werden. Zu beachten ist,
dass neben den genannten Methoden jedes Plugin zusätzliche Methoden afterConfigured und destroy besitzt,
die bei der Initialisierung bzw. bei Zerstörung des Plugins aufgerufen werden (z.B. beim Start bzw. beim Beenden
das nscale Server Application Layers oder auch bei Aktualisierung des PluginsSettings).
| Plugin | Methode | Beschreibung |
|---|---|---|
|
|
Wird aufgerufen, bevor ein Service-Request ausgeführt wird. Ermöglicht es, die Eingabe-Parameter zu verändern oder weitere Aktionen vor Ausführung des Service-Requests durchzuführen. |
|
Wird aufgerufen, nachdem ein Service-Request ausgeführt wurde. Ermöglicht es, den Rückgabewert zu verändern oder weitere Aktionen nach Ausführung des Service-Requests durchzuführen. |
|
|
Wird aufgerufen, wenn innerhalb eines Service-Requests eine Exception geworfen wurde. Ermöglicht es, die Exception zu verändern oder weitere Aktionen durchzuführen (innerhalb einer neuen Transaktion). |
|
|
Wird angeboten für den Untertyp OutOfContextServiceInvocationHook. Ermöglicht es, Aktionen noch vor Beginn des Transaktionskontexts durchzuführen. Achtung: die Methode läuft nur außerhalb des Transaktionskontexts, wenn der Service-Request nicht selber schon in einer Transaktion eingebettet ist (z.B. wenn der Service-Request selbst innerhalb eines Plugins aufgerufen wurde). |
|
|
Wird angeboten für den Untertyp OutOfContextServiceInvocationHook. Ermöglicht es, Aktionen nach Ende des Transaktionskontexts durchzuführen. Achtung: die Methode läuft nur außerhalb des Transaktionskontexts, wenn der Service-Request nicht selber schon in einer Transaktion eingebettet ist (z.B. wenn der Service-Request selbst innerhalb eines Plugins aufgerufen wurde). |
|
|
Wird angeboten für den Untertyp OutOfContextServiceInvocationHook. Ermöglicht es, auf Exceptions nach Ende des Transaktionskontexts zu reagieren. Achtung: die Methode läuft nur außerhalb des Transaktionskontexts, wenn der Service-Request nicht selber schon in einer Transaktion eingebettet ist (z.B. wenn der Service-Request selbst innerhalb eines Plugins aufgerufen wurde). |
|
|
|
Entscheidet, ob ein Service-Request von diesem Plugin abgefangen wird, gibt entsprechend |
|
Wird aufgerufen, wenn Methode |
|
|
|
Hat eine ähnliche Auswirkung wie der ServiceMethodOverwriteHook, ist aber im Gegensatz zu diesem kein Singleton. Ermöglicht es, einen Service-Request abzufangen und zu überschreiben. Der Rückgabewert der Methode ist ein Tupel aus dem eigentlichen Rückgabewert der Methode und einem boolschen Parameter der entscheidet, ob der Service-Request weiterläuft oder nicht. Wenn er abgebrochen wird, werden sowohl weitere ServiceMethodInterfereHooks als auch ein potentiell existierender ServiceMethodOverwriteHook als auch der eigentliche Service-Request nicht mehr durchgeführt. |
|
|
Ermöglicht es, periodisch anfallende Aufgaben automatisiert ausführen zu lassen, indem das Job-Scheduling des nscale Server Application Layers genutzt wird. |
|
|
Wird aufgerufen, wenn der Core des nscale Server Application Layers gestartet wird. |
|
Wird aufgerufen, wenn der Core des nscale Server Application Layers beendet wird. |
|
|
|
Entscheidet, ob eine virtuelle Rendition für eine Ressource verfügbar ist, gibt entsprechend |
|
Wird aufgerufen, wenn Methode |
|
|
Wird aufgerufen, wenn Methode |
|
|
|
Gibt die Definitionen der Custom Computed Properties zurück. |
|
Berechnet die Werte für die definierten Custom Computed Properties. |
|
|
Berechnet die Werte für die definierten Custom Computed Properties in einem Batch und ermöglicht damit eine signifikante Performance-Verbesserung
zur einfachen |
|
|
Gibt die Definitionen der Custom Functions zurück. Diese Methode wird nur aufgerufen, wenn das Plugin das Interface |
|
|
Berechnet die Werte für die definierten Custom Functions. Diese Methode wird nur aufgerufen, wenn das Plugin das Interface |
|
|
|
Wird vor Ausführung jedes SQL-Statements aufgerufen. Ermöglicht es, das Statement und/oder dessen Parameter zu verändern. |
|
|
Ermöglicht es, die Details für das Audit-Log vor Ausführung des Service-Requests zu verändern. |
|
Ermöglicht es, die Details für das Audit-Log nach Ausführung des Service-Requests zu verändern. |
|
|
Ermöglicht es, auf das Schreiben eines Eintrags in das Audit-Log zu reagieren. Diese Methode wird nur aufgerufen, wenn das Plugin das Interface |
|
|
Ermöglicht es, das Schreiben eines Eintrags in das Audit-Log zu unterbinden. Diese Methode wird nur aufgerufen, wenn das Plugin das Interface |
Zusätzlich zu den explizit in der Tabelle genannten Plugins bietet der nscale Server Application Layer im PluginsSetting weitere Plugins wie z.B. eine Reihe von Volltext-Plugins an, die an dieser Stelle nicht weiter betrachtet werden.
2. Multithreading
Ein sehr wichtiger Punkt bei der Implementierung von Application Layer Plugins ist, darauf zu achten, dass die geschriebene Erweiterung sich in den Multithreading-Kontext des Application Layers nahtlos einfügt. Die Multithreading-Funktionalität des Servers, also die Möglichkeit Benutzeranfragen parallel abzuarbeiten, kann nur gewährleistet werden, wenn auch das eingespielte Plugin multithreadingfähig ist.
Multithreadingfähigkeit meint hier,
-
dass die eingespielte Klasse eine parallele Ausführung gewährleistet bzw. diese NICHT unterbindet, z.B. sollte auf die Benutzung von
synchronizedMethoden odersynchronizedCode-Blöcken nach Möglichkeit verzichtet werden. -
Zum zweiten liegt es in der Verantwortung des Plugin-Entwicklers dafür zu sorgen, dass es bei einer parallelen Ausführung des Plugin-Codes zu einer sauberen Trennung der Threads/Java- Instanzen kommt, also dass die für die jeweilige Instanz der Plugin-Klasse gültigen Variablenwerte nicht durch eine weitere Instanz überschrieben oder verändert werden.
Um es noch einmal anders zu betonen: Ein Plugin-Entwickler muss nicht explizit dafür sorgen, dass eine Methode parallel ausgeführt wird, d.h. Entwickler/innen müssen den Thread nicht explizit starten, stoppen oder parallele Threads zusammenführen o.Ä., die grundsätzliche Bereitstellung einer Multithreading-Umgebung obliegt dem Application Layer, aber das Plugin darf die parallele Ausführung zur Laufzeit nicht verhindern!
Dieses Dokument hat nicht den Anspruch, alle Aspekte der Java-Multithreading-Programmierung zu betrachten, hierfür gibt es genügend Fachbücher, Abhandlungen, Artikel usw. Ein paar grundlegende Dinge in Bezug auf eine Multithreading Umgebung sollen aber kurz im Kontext des Application Layers geschildert werden.
2.1. Thread-safe
Wer sich initial mit dem Thema Multithreading auseinandersetzt, dem wird stets im Zusammenhang mit Multithreading das Thema „thread-safe“ über den Weg laufen. Mit Threadsicherheit bzw. Threadsafe ist gemeint, dass eine Klasse oder Methode so aufzubauen ist, dass eine parallele Abarbeitung gewährleistet ist und sich die parallelen Stränge nicht gegenseitig behindern oder manipulieren können, vgl. hierzu auch http://de.wikipedia.org/wiki/Threadsicherheit.
Mit bestimmten Programmierpraktiken kann man die parallele Abarbeitung unterbinden, so z.B. durch
die Deklaration einer Methode als synchronized, hiermit macht man eine Methode auch „threadsicher“
aber in einem anderen Sinne, mit der Konsequenz, dass alle Threads nur nacheinander diese
Methode durchlaufen können (die Threads können eine Methode nur synchron durchlaufen), was im Verbund des
Application Layers dazu führt, dass die Multithreadingfähigkeit aufgehoben bzw. blockiert wird.
Wird zur Laufzeit, nach Einspielen eines Plugins, ein Performanceeinbruch registriert, so kann ein
synchronized Block des Plugins hierfür die Ursache sein. Im schlimmsten Fall kann es durch
einen synchronized Block sogar zu Deadlock-Situationen kommen, etwa wenn innerhalb eines
synchronized Blocks eine API-Methode aufgerufen wird, die wiederum in den synchronized Block
läuft. In diesem Fall hängt der Thread ewig (bis der Server neu gestartet wird).
Synchronisierte Blöcke sollten daher nach Möglichkeit überhaupt nicht benutzt werden. Wenn es sich
gar nicht vermeiden lässt (als letzte Lösung nach Ausschöpfung aller anderen Möglichkeiten), sollte
der synchronized Block nur für die geringstmögliche Anzahl von Zeilen benutzt werden.
2.2. Variablen
java member variables
Eine Variable als Klassen- bzw. „Member variable“ anzulegen ist in einer Multithreading-Umgebung nur dann sinnvoll, wenn der Inhalt der Variablen für alle Requests dieses Plugins IMMER gleich ist, der Inhalt der Variable also nicht potentiell zur Laufzeit verändert wird. Im benutzten Speicher der JVM gibt es auch bei mehreren Instanzen einer Plugin-Klasse nur EINEN Bereich, in dem der Wert der Variablen abgelegt wird. Werte wie z.B. die konkreten Verbindungsparameter zu einer Datenbank oder die konfigurierten Werte für die Längen- und Breitenangaben einer Rendition können mit Member-Variablen abgelegt werden.
java local variables
In einer Multithreading Umgebung sollte man immer mit lokalen Variablen arbeiten. Lokale Variablen im Java-Sinne sind Variablen, die innerhalb einer Methode deklariert und gesetzt werden. Ist es notwendig, Daten über mehrere Methodenaufrufe innerhalb des Plugins zu halten, so sollte man hier mit der Klasse ThreadLocal arbeiten. Vereinfacht gesagt, ist die Klasse ThreadLocal ein Container, der für jeden Thread erzeugt wird und auch sicherstellt, dass jeder Thread seinen Container hat und auch nur auf diesen zugreifen kann. Konkrete Werte können in diesen Container geschrieben und auch wieder ausgelesen werden. Technisch ist es so, dass der „ThreadLocal Container“ solange Bestand hat, wie der Thread Bestand hat.
2.3. Endlosschleifen
Wird ein Plugin aufgerufen und der Plugin-Code selber führt Operationen auf der Schnittstelle aus,
kann es potentiell zu Endlosschleifen kommen, wenn sich das Plugin dadurch immer wieder selbst
aufruft.
Beispiel: Ein Plugin, welches durch einen updateProperties(…) Service-Request getriggert wird und selber im
Ablauf des Plugin-Codes ein updateProperties(…) aufruft.
Um in diesem Fall nicht in eine Endlosschleife zu geraten, ist die Empfehlung, den ersten, initialen
Aufruf des Plugins mittels des ThreadLocal-Mechanismus zu speichern. Beim erneuten Aufruf des Plugins,
getriggert durch den selbst initiierten updateProperties(…) Service-Request, wird die ThreadLocal Variable
ausgelesen und bei Vorhandensein des speziellen Attributs die API Methode nicht erneut ausgeführt.
| Der ThreadLocal-Kontext bzw. der spezielle Container besteht so lange, wie auch der Thread besteht. Wenn also über diesen Mechanismus gesteuert wird, dass ein erneuter, selbst getriggerter Aufruf unterbunden wird, so ist dafür Sorge zu tragen, den Inhalt des ThreadLocal Containers wieder zurückzusetzen, um auch für spätere, clientgetriebene Aufrufe wieder korrekt zu arbeiten (Threads werden in späteren Client-Requests wiederverwendet). Dieses kann beispielsweise in einem try/finally-Block geschehen. |
Prinzipieller Ablauf innerhalb eines Plugins, welches auf updateProperties(…) reagiert und
seinerseits aufgrund eines Attributwertes ein anderes Attribut setzt:
-
Aufruf der Methode
updateProperties(…)durch den Client -
Plugin wird getriggert und fängt den
updateProperties(…)Service-Request ab. -
Plugin prüft den Inhalt des ThreadLocal Kontextes
-
Kontext leer (d.h. erster, initialer Aufruf)
-
Plugin vermerkt im ThreadLocal Kontext den Aufruf des Plugins
-
Plugin führt das nachgelagerte
updateProperties(…)aus -
ThreadLocal Kontext wird wieder zurückgesetzt, um ggf. spätere erneute clientseitige Aufrufe (mit gleichem Thread!) ausführen zu können
-
-
Kontext bereits beschrieben d.h. Aufruf bereits erfolgt, Plugin-Code wurde bereits ausgeführt, keine fachliche Aktion notwendig
-
Wichtig in diesem Kontext ist, zu beachten, dass Methodenaufrufe eines Clients, welche nacheinander über dieselbe Session abgesetzt werden, potentiell immer durch denselben Thread im Server ausgeführt werden. Dadurch steht den Methoden derselbe ThreadLocal Kontext zur Verfügung und auch die Plugins reagieren bei den Aufrufen dementsprechend.
2.4. Beispiel-Code
Das folgende Negativ-Beispiel eines ServiceInvocationHooks zeigt, wie man eine Member-Variable
falsch benutzt und dadurch eine Klasse implementiert, die nicht thread-safe ist: ![]()
private ResourceKey resourceKey;
public Object[] before ( Method method,
Object[] args,
PluginExecutionContext pExecCtx ) {
// ...
this.resourceKey = ermittle_einen_resourceKey();
// ...
return args;
}Wird statt der Member-Variable eine lokale Variable benutzt, ist die Klasse thread-safe: ![]()
public Object[] before ( Method method,
Object[] args,
PluginExecutionContext pExecCtx ) {
// ...
ResourceKey resourceKey = ermittle_einen_resourceKey();
// ...
return args;
}Abschließend noch ein Beispiel zur Vermeidung von Endlosschleifen und zum korrekten Umgang mit ThreadLocal:
private static ThreadLocal < Boolean > recursionFlag = new ThreadLocal<>();
public Object[] before ( Method method,
Object[] args,
PluginExecutionContext pExecCtx ) {
if ( method.getDeclaringClass().equals ( RepositoryService.class ) ) {
if ( method.getName().equals ( RepositoryMethodKey.updateProperties.name() ) ) {
if ( recursionFlag.get() == null ) {
try {
recursionFlag.set ( Boolean.valueOf ( true ) );
pExecCtx.getRepositoryService().updateProperties (...);
} finally {
recursionFlag.set ( null );
}
}
}
}
return args;
}Hinweis: Ab Version 7.1 bietet der PluginRuntimeService eine Methode an, die die Rekursionstiefe
innerhalb eines ServiceInvocationHooks oder eines ServiceMethodInterfereHooks bzw. ServiceMethodOverwriteHooks zurückliefert. In
gewissen Szenarien kann es nützlich sein, diese Information in ThreadLocal zu speichern, z.B. wenn in
einem ServiceInvocationHook in der before-Methode Werte gespeichert werden sollen und in der
afterReturning-Methode ausgewertet werden sollen:
private static ThreadLocal < Integer > recursionLevel = new ThreadLocal<>();
private static ThreadLocal < Object > myValue = new ThreadLocal<>();
public Object[] before ( Method method,
Object[] args,
PluginExecutionContext pExecCtx ) {
Integer level = recursionLevel.get();
if ( level != null && level.intValue() >= pExecCtx.getPluginRuntimeService()
.getPluginRecursionDepth() ) {
// the corresponding afterReturning method did not reset recursion level
// maybe an exception was thrown, so the method never was called
// i have to reset the flag now
recursionLevel.set ( null );
}
if ( method.getDeclaringClass().equals ( RepositoryService.class ) ) {
if ( method.getName().equals ( RepositoryMethodKey.updateProperties.name() ) ) {
// ...
// save recursion level in thread-local, so that the corresponding
// afterReturning method can proceed the method
recursionLevel.set ( pExecCtx.getPluginRuntimeService()
.getPluginRecursionDepth() );
// ...
myValue.set ( … );
// ...
}
}
return args;
}
public Object afterReturning ( Object returnValue,
Method method,
Object[] args,
PluginExecutionContext pExecCtx ) {
Integer level = recursionLevel.get();
if ( level != null && level.intValue() == pExecCtx.getPluginRuntimeService()
.getPluginRecursionDepth() ) {
recursionLevel.set ( null );
// i am in the corresponding afterReturning method and may proceed my method
// ...
Object value = myValue.get();
// ...
}
return returnValue;
}Mit Hilfe dieser Vorgehensweise kann quasi eine Brücke geschlagen werden von der before- zur
dazugehörenden afterReturning-Methode.
2.5. PluginSynchronizationContext
Ab Version 7.6 liefert der Server die Klasse PluginSynchronizationContext mit aus, die ThreadLocal-
Member enthält. Man kann sich dieser Klasse bedienen, um nicht selber ThreadLocal-Variablen
definieren zu müssen. In Version 7.10 liefert der Server innerhalb der Klasse z.B. eine Konstante für
eine PrincipalId mit aus. Man kann mit Hilfe dieser Konstante eine PrincipalId innerhalb eines Plugins
setzen und in einem anderen Plugin auswerten. Beispiel:
PluginSynchronizationContext.set ( PluginSynchronizationContext.REQUEST_CONTEXT_PRINCIPAL_ID, principalId );
Auswertung innerhalb eines anderen Plugins:
String principalId = PluginSynchronizationContext.get ( PluginSynchronizationContext.REQUEST_CONTEXT_PRINCIPAL_ID );
Um innerhalb von eingebetteten Requests (Aufruf einer Service-Methode innerhalb eines Plugins) den
ursprünglichen Principal zu ermitteln, kann im PluginRuntimeService auch die Methode
getInitialPrincipalId() aufgerufen werden.
|
3. Error Handling
Alle in Plugin- und Workflow-Handlern definierten Arbeitsabläufe werden in einer Transaktion abgearbeitet. Tritt hierbei ein Fehler im Server auf, wird ein Rollback für das komplette Plugin (oder z.B. die komplette Workflow-Action) ausgeführt. Die Transaktion wird dabei als „dirty“ markiert. Dadurch verhindert selbst das Trennen einzelner Ausführungsschritte in try-and-catch Blöcke nicht das Zurücksetzen des gesamten Plugin-Programmablaufs. Die Transaktion wird auf jeden Fall bei Beendigung des Service-Requests zurückgerollt.
Die in diesem Unterkapitel getroffenen Aussagen gelten nur dann für Custom-Jobs, wenn in
der Plugin-Konfiguration der Parameter singleTx auf true gesetzt ist. Anderenfalls findet, im
Gegensatz zu allen anderen Plugins, die Ausführung eines Custom-Jobs NICHT in einer
Transaktion statt, sondern jeder abgesetzte Service-Request innerhalb eines Custom-Jobs
läuft in einer eigenen Transaktion.
|
Das „Fangen“ und Interpretieren von Exceptions sollte sehr bewusst erfolgen. Exceptions, die im
Kontext des Application Layers auftreten, führen unweigerlich zum Abbruch der Transaktion. „Im
Kontext des Application Layers“ bedeutet, dass man sich innerhalb des Aufrufs einer Service-Methode,
z.B. updateProperties des RepositoryServices (schreiben von Attributen auf einer Ressource)
befindet. Exceptions, die im (selbstgeschriebenen) Plugin-Code auftreten, führen nur dann zum
Abbruch der Transaktion, wenn die Exception auch im Kontext des Plugins weiterhin geworfen wird.
Wenn der Fehler abgefangen und nicht weitergeleitet wird, bleibt der Server davon unbenommen.
Das folgende Codebeispiel soll die unterschiedlichen Fehlerstrategien zeigen.
/**
* Beispielklasse, die die Fehlerbehandlung am konkreten Beispiel einer Workflow Action
* zeigen soll. Fachlich hat der Code keinen Anspruch auf Sinnhaftigkeit, aber er zeigt
* beide Fälle der möglichen Fehlerbehandlung durch den Plugin-Entwickler.
*
* Fall 1:
* Fehler, die im eigenen Kontext, also nicht im Kontext des nscale Servers auftreten,
* können beliebig behandelt werden.
*
* Fall 2:
* Fehler, die im Kontext des nscale Servers auftreten, führen unweigerlich zum Abbruch
* der Transaktion. Das Abfangen solcher Fehler und weiterer Code-Ablauf innerhalb des
* Plugins ist nicht sinnvoll, da die Transaktion in jedem Fall zurückgerollt wird. Um
* Fehlerzustände zu speichern, muss eine neue Transaktion begonnen werden, z.B. durch
* ein Transaction-Callback.
*
*/
public class WfExampleActionHandler extends DefaultActionHandler
implements PropertyNameConstants {
//------------------------------------------------------------------Constant
private static final long serialVersionUID = 2703710469574488128L;
//--------------------------------------------------------------------Static
private static Logger logger = LoggerFactory.getLogger ( WfExampleActionHandler.class );
//--------------------------------------------------------------------Public
public void execute ( WorkflowExecutionContext wfExecCtx ) throws WorkflowException {
WorkflowRuntimeService wfrService = wfExecCtx.getWorkflowRuntimeService();
String areaName = wfrService.getCurrentDocumentAreaName();
Integer value = null;
// Fall 1
try {
// Die Ermittlung des Wertes erfolgt durch ein externes Verfahren,
// der Server ist nicht beteiligt.
value = kompliziertes_externes_Verfahren();
} catch ( Exception exc ) {
/**
* Tritt an dieser Stelle ein Fehler auf, kann der Plugin-Entwickler entscheiden,
* ob die Action-Klasse abgebrochen werden soll, indem diese oder eine andere
* Exception weiter geworfen wird, so dass die Transaktion des nscale Servers
* zurückgerollt wird
*
* oder ob er hier eine entsprechende Fehlerbehandlung vorsieht und die Exception
* nicht weiter wirft, so dass die Action-Klasse weiterlaufen kann und die
* Transaktion des nscale Servers erfolgreich abgeschlossen werden kann.
*
* Entscheidend hierbei ist, dass die Exception nicht im Server-Kontext aufgetreten
* ist, also nicht bei Aufruf einer Methode aus einem Service, der durch den
* Execution-Context (hier WorkflowExecutionContext) zur Verfügung gestellt wird.
*
*/
// Die Action-Klasse soll weiterlaufen, das Attribut bekommt einen Default-Wert
value = 3;
}
IndexingPropertyName ipn = new IndexingPropertyName ( WFPROPERTYNAME_PROCESSPRIORITY,
areaName );
List < Property > props = new ArrayList<>();
props.add ( new Property ( ipn, value ) );
// Fall 2
try {
// Aufruf einer Service-Methode im Transaktions-Kontext
wfrService.updateProperties ( props );
} catch ( WorkflowException exc ) {
/**
* Zu diesem Zeitpunkt ist die zugrundeliegende Transaktion des nscale Servers
* bereits als "dirty" markiert, d.h. unabhängig davon, was hier und im weiteren
* Verlauf noch passiert, wird die Transaktion zurückgerollt. Das explizite Fangen
* dieser Server-Exception ist ggf. sinnvoll, um eine Fehlerbehandlung zu
* ermöglichen, z.B. um Log-Ausgaben zu schreiben.
*
*/
logger.error ( "Mein Attribut konnte nicht geschrieben werden, schade..." );
/**
* Die Exception sollte in diesem Fall unbedingt weiter geworfen werden, da eine
* weitere Ausführung des Plugin-Codes sinnlos ist und es sonst zu einem späteren
* Zeitpunkt zu einer Hibernate-Exception kommt.
*
*/
throw exc;
}
}
//-------------------------------------------------------------------Private
private Integer kompliziertes_externes_Verfahren() {
return 1;
}
}3.1. Benutzerdefinierte Transaktionen
Besteht die Notwendigkeit, im Fehlerfall eine Information auch nach Zurückrollen der Transaktion zu
erhalten, kann man sich des Application Layer TransactionCallback Verfahrens bedienen.
Eine benutzerdefinierte Transaktion wird implizit über das Java-Interface TransactionCallback < E >
gesteuert. Eine Klasse, die dieses Interface und die dazugehörige Methode doInTransaction()
implementiert, kann Aufgaben (z.B. updateProperties(…)) unabhängig von der äußeren Transaktion in
einer eigenen, inneren Transaktion ausführen. Alle Methodenaufrufe innerhalb der doInTransaction() Methode
werden in der inneren Transaktion ausgeführt.
Der PluginRuntimeService bzw. WorkflowRuntimeService enthalten eine Methode execute(…), die
als Parameter eine Implementierung von TransactionCallback erwartet.
Beim Aufruf von execute wird implizit
-
eine neue Transaktion gestartet,
-
das Abarbeiten der über die nscale Server Application Layer-Schnittstelle definierten Schreib- und Leseoperationen durchgeführt,
-
die Transaktion mit
commitbeendet, wenn alle Aufgaben erfolgreich ausgeführt werden konnten, oder mitabortbeim Auftreten eines Fehlers. In diesem Fall wird eine Exception geworfen, die ein Rollback auf alle über das TransactionCallback-Objekt erzeugten Datenbestände bewirkt.
3.1.1. Fehlerbehandlung
Wird die in der inneren Transaktion im Fehlerfall geworfene Exception in der Umgebung der äußeren Transaktion abgefangen, dann hat die Exception keine Auswirkung auf die äußere Transaktion. Diese kann trotz eines auftretenden Fehlers und das damit verbundene Zurückrollen der inneren Transaktion weiter ausgeführt werden. Soll als Konsequenz eines Fehlers, der innerhalb der inneren Transaktion aufgetreten ist, auch die äußere Transaktion abgebrochen werden, so darf die Exception der inneren Transaktion nicht gefangen werden, bzw. muss eine Exception weiter geworfen werden.
Im anderen Fall, wenn die innere Transaktion abgeschlossen ist und es zu einem nachgelagerten Fehler in der äußeren Transaktion kommt, wird die äußere Transaktion zurückgerollt, wobei dies auf den Zustand der inneren Transaktion keinen Einfluss hat.
Beispiel: Wurden innerhalb der inneren Transaktion Änderungen z.B. in einer fremden Datenbank vorgenommen, so sind diese auch dann noch vorhanden, selbst wenn es in der äußeren Transaktion zu einem Fehler kommt und diese zurückgerollt wird. Dieser Fall wird auch gerne dazu benutzt, einen Fehlerstatus in ein Feld zu schreiben, der auch nach Zurückrollen der äußeren Transaktion noch Bestand hat. Ohne diesen Mechanismus würde auch der gesetzte Fehlerstatus beim Zurückrollen der Transaktion wie alles andere auch zurückgerollt und damit nicht persistiert.
Hierzu existiert eine Beispielklasse, die den Aufruf einer benutzerdefinierten Transaktion zeigt. Die
Beispielklasse RunTransactionCallback.java befindet sich im /samples Verzeichnis des
nscale SDKs (der Advanced-Connector API).
Weitere Hinweise und Designempfehlungen in diesem Zusammenhang finden Sie im folgenden
Abschnitt über Deadlocks und Blocking Locks.
3.2. Deadlocks / Blocking Locks
Als Deadlock wird in der Informatik ein Zustand bezeichnet, bei dem mehrere beteiligte Prozesse Ressourcen halten und gleichzeitig auf eine weitere Ressource warten, die schon von einem anderen beteiligten Prozess gehalten wird. Auf diese Weise blockieren sich die Prozesse gegenseitig und alle beteiligten Prozesse warten ewig, da kein Prozess eine benötigte Ressource freigibt.
Konkrete Deadlocks werden von den Datenbanken in der Regel als solche erkannt und selbstständig durch die Datenbank aufgelöst. In der Regel sind zwei Transaktionen beteiligt, von der eine von der Datenbank als Deadlock-Opfer ausgewählt und automatisch zurückgerollt wird. Man erkennt dies daran, dass im Log-File eine entsprechende Exception protokolliert wird, in der die Auswahl des Deadlock-Opfers gemeldet wird.
Das Problem von Deadlocks kann in Multithreading-Umgebungen potentiell immer auftreten. Theoretisch ließen sich Deadlocks vermeiden, wenn alle Prozesse ihre benötigten Ressourcen immer in der gleichen Reihenfolge anfordern würden. Im Falle des nscale Server Application Layers lässt sich dies leider nicht realisieren, da die Reihenfolge des Zugriffs auf Datenbank-Tabellen durch das eingesetzte Hibernate-Framework bestimmt wird und nur bedingt vorgegeben werden kann. Je nach angebundener Datenbank kann das Problem von Deadlocks mehr oder weniger stark ausgeprägt sein, dies hängt von der verwendeten Lock-Strategie des verwendeten Datenbank-Dialekts ab. Vor allem der Microsoft SQL Server lockt Tabellen sehr restriktiv, daher ist unter dieser Datenbank vermehrt mit Deadlocks zu rechnen. Falls dies gehäuft auftritt, sollte geprüft werden, ob der Snapshot Isolation Level (sogenannter Oracle-Modus) benutzt werden kann.
Wie gesagt können Deadlocks von der Datenbank in der Regel selbstständig erkannt und aufgelöst werden. Es gibt aber Fälle, in denen die Datenbank nicht in der Lage ist, diesen automatisch aufzulösen, weil er nicht als (Datenbank) Deadlock klassifiziert werden kann. In diesem Fall sprechen wir von einem Blocking Lock. Ein Blocking Lock tritt z.B. auf, wenn eine äußere Transkation eine Ressource hält, die auch von einer inneren Transaktion (z.B. in einem TransactionCallback) benötigt wird. Ist so ein Zustand erreicht, hängen beide Transaktionen ewig (bis evtl. ein Transaktions-Timeout zuschlägt).
Man kann durch Einhaltung gewisser Designempfehlungen die Wahrscheinlichkeit eines Blocking Locks aber gering halten. Als Faustregel kann man sagen, dass der TransactionCallback-Mechanismus bzw. das Starten von benutzerdefinierten Transaktionen innerhalb des Plugins nur sehr bedacht erfolgen sollte und nur da, wo es sinnvoll und notwendig ist. Erfahrungsgemäß treten Blocking-Lock-Situationen immer nur in Verbindung mit dem TransactionCallback-Mechanismus auf.
Wenn man mit dem TransactionCallback-Mechanismus (benutzerdefinierte Transaktionen) arbeitet,
sollte man folgende Grundregeln beachten bzw. seinen bestehenden Code dahingehend anpassen:
Der TransactionCallback-Mechanismus kann immer dann problematisch sein, wenn schreibende
Operationen (z.B. updateProperties(…)) im Plugin und auch innerhalb des TransactionCallback
Blocks (setzen eines Fehlerstatus) passieren, vor allem wenn dies gleiche Tabellen und Zeilen
betreffen. Ändern Sie ihren Code nach Möglichkeit dahingehend ab, dass schreibende Operationen in
der äußeren Transaktion erst nach dem TransactionCallback Block aufgerufen werden. Technisch
sorgen Sie so dafür, dass es zu keinen Blocking-Lock-Situationen auf Seiten der Datenbank durch sich
gegenseitig blockierende Schreiboperationen kommen kann.
Die folgenden Abbildungen enthalten Fallbeispiele und Empfehlungen, wie der Plugin-Code angepasst werden kann, um die Wahrscheinlichkeit von Blocking Locks zu minimieren.
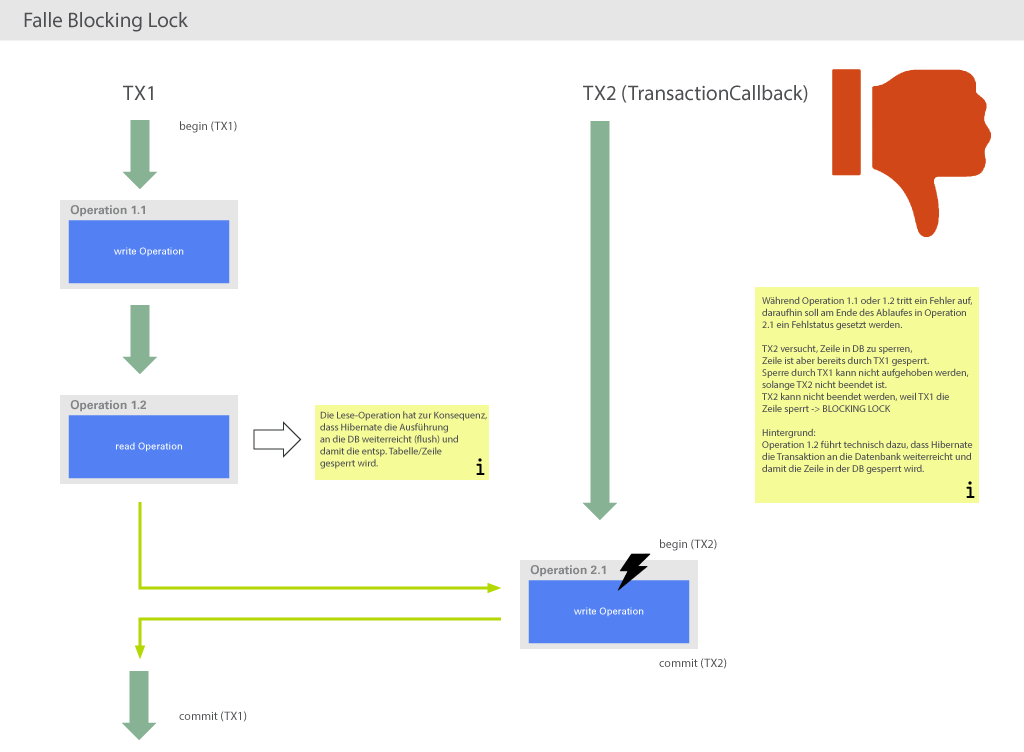
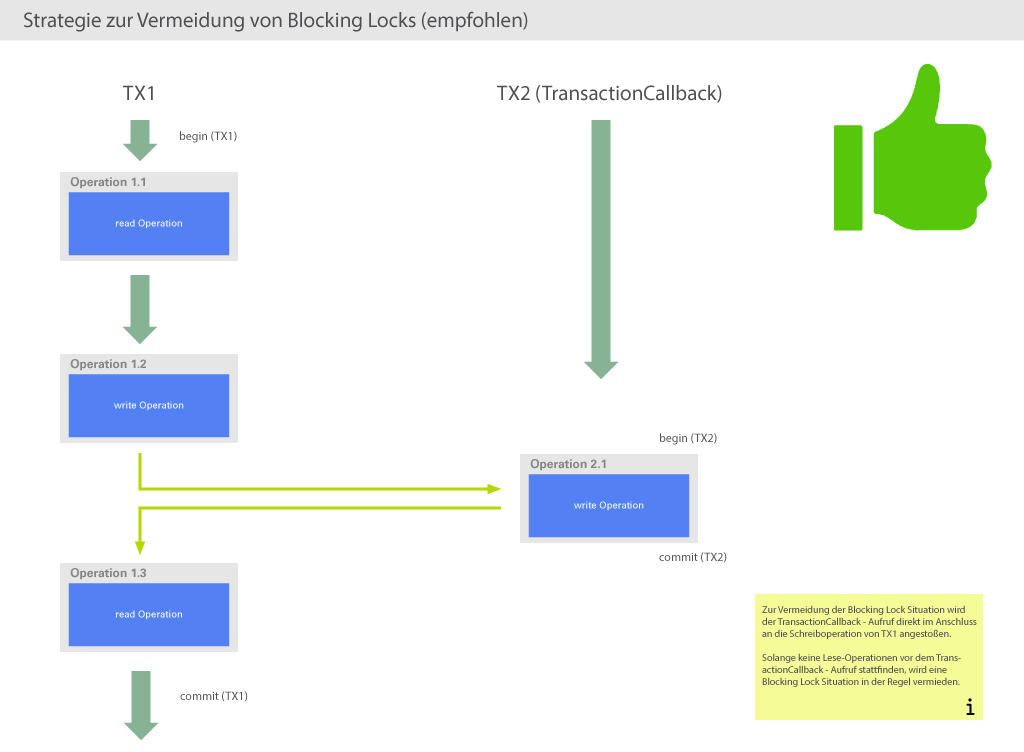
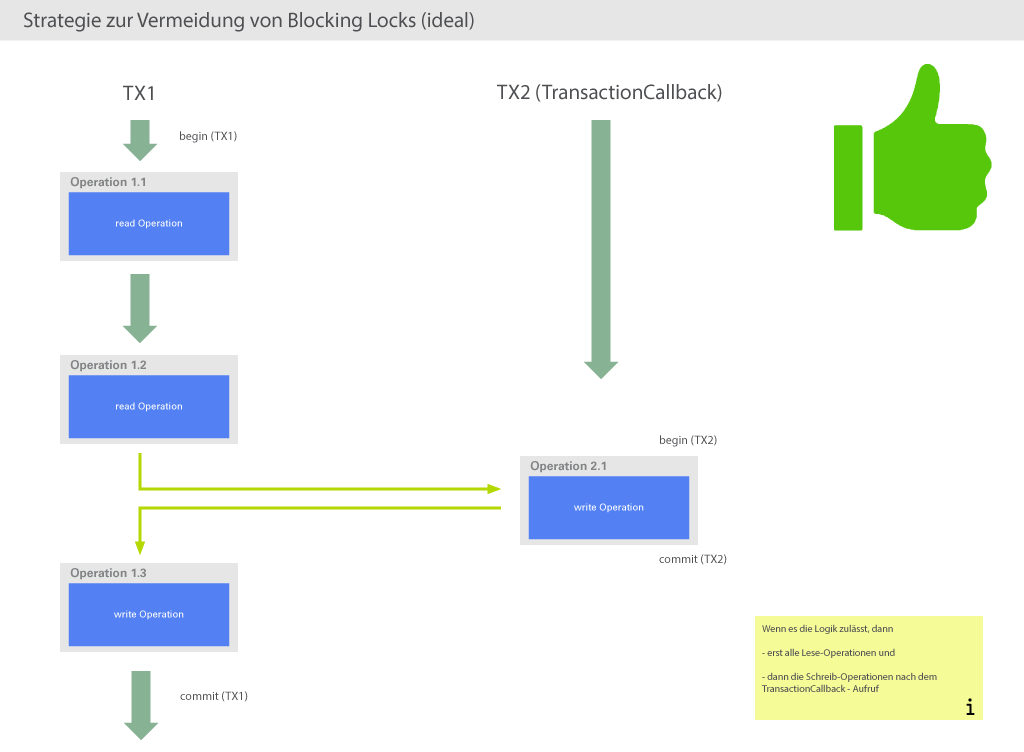
Das Fallbeispiel aus Abbildung 3 ist der Idealfall, hier wird es nie zu Blocking-Lock-Situationen kommen.
Allerdings ist es fraglich, ob diese Vorgehensweise auch praxisrelevant ist, da es vermutlich eher nötig sein
wird, schon vor Ausführung eines TransactionCallbacks schreibend auf die Datenbank zugreifen zu müssen.
Daher ist das Fallbeispiel aus Abbildung 2 die empfohlene Vorgehensweise, auch hier wird es kaum zu
Blocking-Lock-Situationen kommen (es sei denn, Hibernate führt ausgerechnet vor Ausführung der inneren
Transaktion ein auto-flush aus, dies dürfte aber nur ein theoretisches Problem sein).
Kurz gesagt kann man folgende Strategie ausgeben: Zwischen einer schreibenden Operation der äußeren und einer schreibenden Operation der inneren Transaktion darf kein Lesevorgang auf demselben Datenbestand stattfinden. Was derselbe Datenbestand ist, ist vom verwendeten Datenbank-System abhängig, es kann z.B. die selbe Tabelle oder die selbe Zeile bedeuten, je nachdem, wie restriktiv die Datenbank lockt. Grundsätzlich ist es erstrebenswert (wenn es die Logik des Plugins zulässt), dass alle lesenden Zugriffe vor allen schreibenden Zugriffen stattfinden, da so auch Sperren auf Datenbank-Tabellen möglichst kurz gehalten werden und die Gefahr von Deadlocks verringert wird.
3.3. OutOfContextServiceInvocationHook
Seit Version 7.3 unterstützt der Server eine erweiterte Form des ServiceInvocationHooks, den OutOfContextServiceInvocationHook. Dessen Methoden werden außerhalb der eigentlichen Transaktion eines Service-Requests aufgerufen und eignen sich daher auch, bei zurückgerollten Transaktionen Fehlerzustände zu schreiben. Damit stellt der OutOfContextServiceInvocationHook eine Alternative zu TransactionCallbacks dar. Der Vorteil ist, dass Blocking Locks vermieden werden.
| Die Methoden des OutOfContextServiceInvocationHooks laufen nur dann außerhalb der Transaktion, wenn der Service-Request nicht eingebettet ist, also nicht innerhalb eines Plugins aufgerufen wurde. Wenn der Service-Request eingebettet ist, läuft die eigentliche Transaktion noch. In diesem Fall verhält sich ein OutOfContextServiceInvocationHook wie ein ServiceInvocationHook. |
4. Plugin-Versionierung und Logging
Aktiviert man die Plugins-Logger[1], so kann man anhand der Protokolldateien erkennen, welche Arten von Plugins im Server initialisiert werden und welche aufgerufen werden. Was man nicht aus der Protokolldatei herauslesen kann, ist die konkrete Version des Plugins und den Codedurchlauf selber.
4.1. Versionierung
In der Praxis ist es oft so, dass mit weiteren Kundenanforderungen auch neue Versionen von bestehenden Plugins notwendig werden. Um zweifelsfrei belegen zu können, welche Version des Plugins aktuell im Server seinen Dienst tut, ist dies nur durch geeignete Protokollausgaben innerhalb des Plugins sinnvoll möglich.
Es ist technisch nicht möglich, auf generischem Weg automatisch durch den Application Layer für eine entsprechende Protokollierung zu sorgen. Diese Verantwortung liegt bei dem Entwickler des Plugins.
Unsere Empfehlung ist, eine Logausgabe entsprechend dem Beispiel aufzubauen und diese während
der Initialisierung des Plugins (Methode afterConfigured) grundsätzlich mit auszugeben, zusätzlich
in der Protokollierungsstufe debug oder trace bei jedem Methodenaufruf des Plugins. Somit ist immer
gewährleistet, zu Beginn aber auch zur Laufzeit, über die konkrete Version des Plugins zweifelsfrei
informiert zu sein.
private static final String PLUGIN_VERSION = "1.1.3";
public static String getPluginVersionInfo ( PluginExecutionContext pExecCtx ) {
String log = "[plugin version: " + PLUGIN_VERSION +
", plugin name: " + pExecCtx.getPluginRuntimeService().getPluginName() +
", author: Ceyoniq Technology GmbH]";
return log;
}Es versteht sich von selbst, dass die Version des Plugins bei jeder Anpassung des Plugin-Codes entsprechend angepasst werden muss!
Werden die Plugins als JAR oder ZIP-Archive geladen, so kann man diese mit Versionsnummern
versehen, z.B. myPlugins-1.0.jar.
Ab Version 7.2 können sowohl Plugins als auch die darin benutzten Klassen und Dateien Metainformationen enthalten, wie z.B. den Ersteller, die Versionsnummer oder das Änderungsdatum. Diese Informationen können bei Bedarf ausgelesen und mit ausgeloggt werden. Beispiel zum Lesen der PluginInfo:
public PluginInfo getPluginInfo ( PluginExecutionContext pExecCtx ) {
PluginsSetting ps = pExecCtx.getConfigurationService().getPluginsSetting();
return ps.getClassPluginFiles().get ( "MyClass.class" ).getInfo();
}Eine detaillierte Beschreibung der Möglichkeiten inkl. einer konkreten Empfehlung, welche Felder wie zu setzen sind, finden Sie in der offiziellen Dokumentation zum nscale Administrator.
4.2. Logging
Wir empfehlen, immer den Standard Application Layer Logging Mechanismus zu verwenden. Eine Logger-Instanz erhält man, indem sie in der Klasse instanziiert wird:
-
private static Logger logger = LoggerFactory.getLogger ( MyClass.class );
Die im ExecutionContext (z.B. PluginExecutionContext) angebotene Methode getLogger() sollte
nicht mehr verwendet werden, da sie einen Logger der veralteten log4j1-Library zurückliefert.
|
Es sollten mindestens so viele Logausgaben implementiert werden, dass alle Schritte innerhalb des Plugins in der Protokolldatei erscheinen und man ohne Code den Ablauf des Plugins nachvollziehen kann.
Unsere Empfehlung ist es, die Version des Plugins während der Initialisierung als INFO Message herauszugeben und Informationen zum Ablauf des Plugins als DEBUG oder TRACE Message.
Logausgaben mittels System.out.println() sind auf jeden Fall zu vermeiden. Solche Ausgaben
landen in der Standardausgabe, was beim nscale Server Application Layer die Server-Protokolldatei ist.
Dieser Befehl sollte höchstens in der Debug-Phase benutzt werden und hat in einem produktiven Plugin nichts
verloren!
4.2.1. Beispiel
Der Plugin-Klassenname sei com.ceyoniq.plugin.MyClass. Zum Aktivieren des Loggers auf Protokollierungsstufe
DEBUG muss in der Log-Konfigurationsdatei (per Default instance1-log.xml) folgender Eintrag hinzugefügt werden:
<Logger name="com.ceyoniq.plugin.MyClass" level="debug">
Das Logging wird standardmäßig in die Datei logs/nscalealinst1.log geschrieben. Bei umfangreichen
Ausgaben ist ein Umleiten in eigene Protokolldateien möglich, es muss dazu in der Log-Konfigurationsdatei
ein neuer Appender definiert werden, die Einträge könnten z.B. folgendermaßen aussehen:
<Logger name="com.ceyoniq.plugin.MyClass" level="debug" additivity="false">
<AppenderRef ref="myAppender"/>
</Logger>
<Appenders>
<RollingFile name="myAppender"
fileName="logs/myFile.log"
filePattern="logs/myFile.log_%d{yyyy-MM-dd}.log">
<PatternLayout pattern="%d %-5p [%t] %c - %m%n"/>
<Policies>
<TimeBasedTriggeringPolicy modulate="true"/>
</Policies>
<DefaultRolloverStrategy max="2147483647"/>
</RollingFile>
</Appenders>Bei der Erweiterung der Log-Konfigurationsdatei ist man völlig frei, es steht einem hier die volle Mächtigkeit
des log4j-Frameworks zur Verfügung, siehe z.B. https://logging.apache.org/log4j/2.x/.
5. Memory-Leaks
Memory-Leaks entstehen immer dann, wenn Objekte erzeugt werden und diese nach Gebrauch nicht wieder aus dem Speicher entfernt werden. In aller Regel kümmert sich Java (technisch der Garbage Collector) selbstständig um das Aufräumen des Speichers. Es gibt aber wie immer zahlreiche Sonderfälle, wo ein automatisches Aufräumen durch Java nicht erfolgen kann, da noch Referenzen auf ein Objekt durch ein anderes Objekt gehalten werden.
Wichtig ist es, „zu schließende“ Objekte auch im Fehlerfall zu schließen! Unsere Empfehlung in dieser
Hinsicht lautet grundsätzlich mit einem Java finally Block zu arbeiten, d.h. Objekte, die auf jeden
Fall geschlossen werden müssen (z.B. ein java.sql.ResultSet) im finally Block zu schließen, um
sicherzustellen, dass diese Abarbeitung auch im Fehlerfall geschieht.
Der folgende Beispielcode zeigt das empfohlene Schließen der Streams und des Contents im finally Block:
try {
// Eigentlicher code
} catch ( Exception exc ) {
// Fehlerhandling
} finally {
// Code hier, wird immer auch im Fehlerfall aufgerufen
}
ExtendedContent ec = null;
InputStream is1 = null;
InputStream is2 = null;
try {
is1 = …
is2 = …
ec = …
} catch ( Exception exc ) {
logger.error ( exc.getMessage() );
} finally {
try {
if ( ec != null ) {
ec.close();
}
} catch ( Exception exc ) {
// do nothing or log exc
}
try {
if ( is1 != null ) {
is1.close();
}
} catch ( IOException exc ) {
// do nothing or log exc
}
try {
if ( is2 != null ) {
is2.close();
}
} catch ( IOException exc ) {
// do nothing or log exc
}
}„Beliebte“ Kandidaten, um Memory-Leaks zu erzeugen, sind z.B. im Fehlerfall nicht geschlossene Statements und ResultSets, geöffnete aber nicht wieder geschlossene Streams jeglicher Art usw.
Auf jeden Fall explizit zu schließende nscale Objekte sind z.B. alle nscale Content und ExtendedContent Objekte. Werden diese Objekte vom Server angefordert, beinhalten sie (in der Regel) eine StorageLayer-Connection, die so lange gehalten wird, bis der (Extended-)Content geschlossen wird. Nicht geschlossene (Extended-)Content führen also nicht nur potentiell zu Memory-Leaks, sondern ebenso zu einem Connection-Leak. Sobald der StorageLayer Connection Pool erschöpft ist, können keine Operationen mehr auf dem StorageLayer durchgeführt werden und der nscale Server Application Layer muss neu gestartet werden.
Wird mit mehr als einem zu schließenden Objekt gearbeitet, ist immer jedes Objekt separat zu
betrachten. Jedes Objekt sollte seinen eigenen try/catch Block bekommen, in dem es geschlossen wird.
Insbesondere Streams (z.B. InputStreams) müssen im finally oder im catch beim Schließen (Aufruf der close()-Methode)
mit einem erneuten try/catch umgeben werden. Dies sollte pro Objekt geschehen (siehe Code-Beispiel
oben für die Streams is1 und is2). Ansonsten würden beim Auftreten eines Fehlers während des Schließens weitere
Objekte nicht mehr geschlossen.
Eclipse bietet als Lösung für ein is1.close(); an, die Zeile automatisch mit einem try/catch zu umgeben. Der
dann generierte Standard Code enthält aber oft im catch Fall eine e.printStackTrace() Anweisung.
Ausgaben egal welcher Art nach system.out sind aber nicht gewünscht und sollten entfernt werden, da sie
unkontrolliert ausgegeben werden und somit nur die Fehlersuche und -analyse erschweren (siehe auch Logging).
Server Methoden, die ein zu schließendes Objekt als Parameter enthalten (wie z.B. ein ExtendedContent),
brauchen nicht vom aufrufenden Code geschlossen werden, in diesem Fall ist der Server für das Schließen
verantwortlich. Im Gegensatz dazu gilt für Methoden, die ein zu schließendes Objekt als Rückgabewert enthalten
(wie z.B. getExtendedContent(…)), dass der aufrufende Client bzw. das Plugin für das Schließen verantwortlich ist.
|
5.1. AutoCloseable
Seit Version 7 unterstützt Java das try-with-resources Statement, mit dessen Hilfe Objekte automatisch
geschlossen werden. So ein Statement kann für Klassen benutzt werden, die das AutoCloseable
Interface implementieren. Es bekommt einen unsichtbaren finally Block, in dem die close Methode
aufgerufen wird. In Advanced Connector Version 7.8 erweitern die beiden Interfaces ExtendedContent
und Session das AutoCloseable Interface. Damit sind z.B. folgende Statements möglich:
try ( ExdendedContent content = repService.getExtendedContent ( resourceKey ) ) {
//...
}
try ( Session session = new AdvancedConnector().login ( null ) ) {
//...
}6. Offiziell freigegebene API-Klassen
6.1. Plugin Entwicklung (vor 9.2)
Die Server-Library beinhaltet auch Klassen, die nur intern verwendet werden, aber nicht zur offiziellen
Schnittstelle gehören. Wenn diese internen Klassen auch in Eigenentwicklungen (z.B. Plugins)
verwendet werden, geschieht dies auf eigene Gefahr, da nicht gewährleistet ist, dass diese Methode
(oder die ganze Klasse) in der nächsten Version des Servers noch vorhanden ist, und auch, wenn die
Methode noch vorhanden ist, kann sich ihre Wirkungsweise verändert haben. Grundsätzlich gilt, dass
nur Klassen freigegeben sind, die in durch JavaDoc dokumentierten Packages liegen. Im Zweifel muss
dies durch den Entwickler im JavaDoc kontrolliert werden. Explizit nicht freigegeben sind alle Packages
mit Suffix impl und persist. Ebenfalls NICHT freigegeben ist das Package com.ceyoniq.nscale.al.core.util,
eine Verwendung der darin enthaltenen Klassen (inklusive CollectionUtils) wird NICHT
empfohlen und geschieht auf eigene Gefahr.
Einige nützliche Klassen, die im Package com.ceyoniq.nscale.al.core.common liegen und damit zur
offiziellen Schnittstelle gehören:
-
PropertyNameConstants: Alle Namen der Standardattribute des nscale Server Application Layers finden sich in dieser Klasse als Konstanten. -
PropertyValueConstants: Alle Standardwerte bzw. Ausprägungen (Delete State, Error State, usw.) des nscale Server Application Layers finden sich hier. -
FulltextState: Alle Standardwerte bzw. Ausprägungen im Bereich Volltext finden sich hier. -
ServiceMethodKey: Alle Namen der Methoden, die in Services des nscale Server Application Layers enthalten sind, werden in Ableitungen dieses Interfaces angeboten.
6.2. Plugin-API mit der Version 9.2
Um zukünfitig die Core-Entwicklung von Seiten der Ceyoniq und Ihre eigene Plug-in-Entwicklung
besser zu trennen, wird al-core in Version 9.2 in mehrere logische Teile aufgetrennt.
Von dieser Trennung ist nur die sogenannte Plug-in-API betroffen, die bislang im JAR al-core enthalten
war. Die im JAR al-api enthaltene Basis-API ist nicht betroffen.
Die al-core Library ist nun in die folgenden neuen JAR-Dateien geteilt:
-
al-plugin-api
-
al-plugins
-
al-plugin-scihh
-
al-plugin-signatures
-
al-core
Die Auftrennung führt nicht zu Inkompatibilitäten zwischen verschiedenen nscale-Versionen, da der Java Classpath zur Laufzeit wieder alle Klassen enthält.
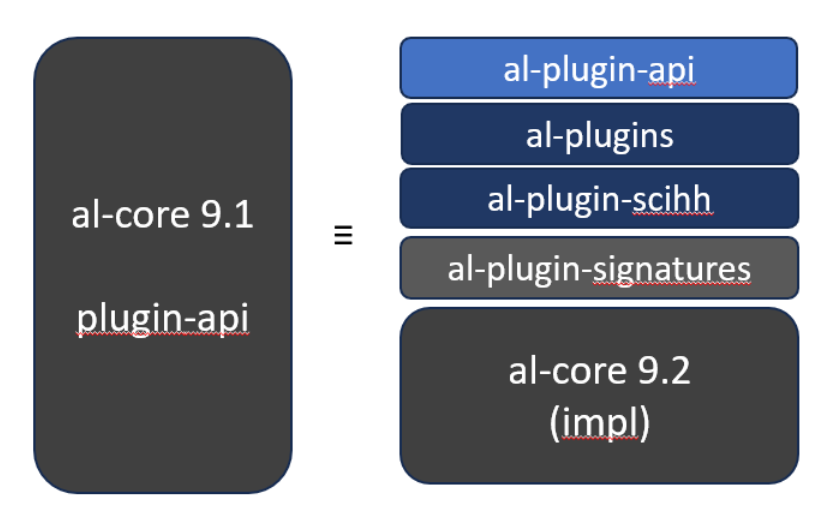
6.2.1. Beschreibung der JARs ab Version 9.2
al-plugin-api
Der Teil von al-core, der für die Plug-in-API relevant ist, wird in die neue JAR al-plugin-api verschoben.
Diese JAR enthält alle freigegebenen Klassen und Packages, die in der Lösungsentwicklung
verwendet werden können.
Bei der Lösungsentwicklung kann jetzt gegen die al-plugin-api programmiert werden. Bei Zugriffen
auf al-core interne Klassen compiliert der Code nicht mehr. Unbeabsichtigte Verwendung von
internen Klassen kann so zukünftig ausgeschlossen werden.
al-plugins
Die Implementierungen von Standard Plug-ins werden in die neue JAR al-plugins verschoben. Diese
JAR enthält dabei Plug-ins für Funktionen wie XRechnung, virtuelle Renditions, alte Rendition Service
Java Klassen und Workflow Actions.
Die Java Packages im Projekt al-plugins sind zum Teil identisch zum Projekt al-plugin-api.
Da sich die Implementierungen der Klassen und Packages in al-plugins ändern können, sollten diese
nicht in eigenen Plug-ins benutzt oder abgeleitet werden. Wir empfehlen, die Verwendung von al-plugins
in der Migrationsphase schnellstmöglich durch Inhalte von al-plugin-api abzulösen.
al-plugin-scihh
Der als „deprecated“ markierte SingleContentItemHookHandler, auch bekannt als Metadaten-Extraktor, ist mit seinen Abhängigkeiten in die JAR „al-plugin-scihh“ ausgelagert worden.
Dieses Projekt wird in späteren Versionen entfernt.
al-plugin-signatures
Die Governikus Anbindung an DATA Aeonia und DATA Varuna werden in die JAR al-plug-signatures
ausgelagert. Dieses Java Klassen sollten nicht benutzt werden.
6.2.2. Custom Plug-in übersetzen
Hier die Einbindung der "al-plugin-api" per Gradle:
dependencies {
// al-plugin-api ( main artifact - includes also dependency al-api )
compileOnly 'com.ceyoniq.nscale.applicationlayer:al-plugin-api:9.2.1000'
// al-plugins ( only for compatibility )
compileOnly 'com.ceyoniq.nscale.applicationlayer:al-plugins:9.2.1000'
}Die Benutzung von "al-plugins" und "al-plugin-scihh" (deprecated) ist nicht empfohlen, aber in der Migrationsphase noch möglich.
7. Performance
Der nscale Server Application Layer ist so konzipiert, dass er auch mit Massendaten performant umgehen kann. Es wurde besonders viel Wert darauf gelegt, dass gerade bei sehr teuren Operationen wie etwa Suchen auf der Datenbank die effizienteste Vorgehensweise gewählt wird. Leider hat sich in der Praxis gezeigt, dass durch ungeschickte Programmierung von Plugins die Performance des Servers ausgebremst oder sogar zerstört wird. Es gibt ein paar Regeln, die bei der Implementierung von Plugins zu beachten sind, um diese Fehler zu vermeiden.
7.1. Reihenfolge der Überprüfungen der Zuständigkeit optimieren
Meistens sollen Plugins nur auf bestimmte Service-Methoden reagieren und der erste Schritt des Plugins besteht oft darin zu erkennen, ob das Plugin greifen soll oder nicht. Bei der Ermittlung der Zuständigkeit sollte unbedingt darauf geachtet werden, dass zuerst die weniger zeitaufwändigen Kriterien überprüft werden und erst am Ende die zeitaufwändigen. Es sollte klar sein, dass z.B. ein ServiceInvocationHook bei JEDEM Service-Request durchlaufen wird, d.h., wenn schon die erste Zeile ein teurer Methodenaufruf ist, wird JEDER Request ausgebremst.
Schlecht ist also z.B. folgende Vorgehensweise: ![]()
if ( ermittle_aufwaendige_Kriterien() ) {
if ( method.getDeclaringClass().equals ( RepositoryService.class ) ) {
if ( method.getName().equals ( RepositoryMethodKey.updateProperties.name() ) ) {
// proceed
}
}
}Richtig ist folgende Reihenfolge: ![]()
if ( method.getDeclaringClass().equals ( RepositoryService.class ) ) {
if ( method.getName().equals ( RepositoryMethodKey.updateProperties.name() ) ) {
if ( ermittle_aufwaendige_Kriterien() ) {
// proceed
}
}
}7.2. Anzahl der Service-Requests minimieren
Jeder Service-Request ist potentiell teuer. Die Anzahl der Requests sollte minimiert werden, insbesondere sollte es keine redundanten Requests geben. Es muss auch bedacht werden, dass vor allem Service-Requests auf dem RespositoryService und in etwas geringerem Maße WorkflowService teuer sein können, da hier mit Massendaten gearbeitet wird. Weniger bedenklich sind Aufrufe des ConfigurationService, da die Konfiguration komplett im Speicher gehalten wird und weniger Datenbank- Statements benötigt werden (wenngleich z.B. für die Rechteprüfung doch einige abgesetzt werden müssen).
Es folgt wieder ein Negativbeispiel aus dem täglichen Leben: ![]()
for ( int i = 0; i < cfgService.getObjectclasses ( „myDocArea“ ).size(); i++ ) {
Objectclass obj = cfgService.getObjectclasses ( „myDocArea“ ).get ( i );
}Hier wird bei n vorhandenen Objektklassen n + 1 mal redundant die Server-Methode
getObjectclasses(…) aufgerufen, korrekt wäre es folgendermaßen: ![]()
List < Objectclass > objectclasses = cfgService.getObjectclasses ( „myDocArea“ );
for ( int i = 0; i < objectclasses.size(); i++ ) {
Objectclass obj = objectclasses.get ( i );
}Bei dieser Vorgehensweise wird der Server nur einmal angefragt.
Da dieses Beispiel nur den ConfigurationService betrifft, sind die Konsequenzen nicht ganz so
dramatisch. Fatal ist aber z.B. folgendes Negativbeispiel für den RepositoryService: ![]()
List < PropertyName > propNames = new ArrayList<>();
propNames.add ( new IndexingPropertyName ( PROPERTYNAME_DISPLAYNAME, "DA1" ) );
ResourceResults res = repService.search ( root, "where objectclass = 'D1'" );
for ( int i = 0; i < res.getResultCount(); i++ ) {
ResourceKey resourceKey = res.getResultTable().getResourceKeys() [ i ];
List < Property > props = repService.getProperties ( resourceKey, propNames );
}Hier wird eine Suche abgesetzt und für jede gefundene Ressource wird mittels getProperties der
Anzeigename geholt. Die Konsequenz ist, dass bei einem ResultSet mit 1000 Treffern insgesamt 1001
Select-Statements abgesetzt werden, benötigt würde aber nur ein Select-Statement, wenn die
benötigten Attribute gleich mit der Suche abgefragt würden: ![]()
ResourceResults res = repService.search ( root, "select displayname where objectclass = 'D1'" );Fazit: Der Entwickler eines Plugins muss sich Gedanken machen, welche Informationen er benötigt, um diese Informationen dann mit der geringstmöglichen Anzahl von Service-Requests abzufragen.
Ein weiteres Beispiel, wie man Service-Requests einsparen kann, ist die Benutzung der Klasse
ResourceKeyInfo (ab Version 7.1). Mit Hilfe dieser Klasse kann man auf Client-Seite an Informationen
zu einem ResourceKey gelangen, ohne eine Service-Methode aufzurufen, etwa folgendermaßen, um an
den Dokumentenbereich zu gelangen:String documentArea = new ResourceKeyInfo ( myResourceKey ).getDocumentAreaName();
|
7.3. Suchen optimieren
Der wohl teuerste Methodenaufruf ist eine Suche im RepositoryService. Auch hier gibt es ein paar Regeln, die unbedingt zu beachten sind, um eine zusätzliche, unnötige Belastung des Servers zu vermeiden.
7.3.1. Optimierung der Select-Klausel
Es sollten nur die Attribute abgefragt werden, die auch wirklich benötigt werden, keine
zusätzlichen. Insbesondere sollten überhaupt keine Attribute abgefragt werden, wenn man bei
einer Suche nur an die ResourceKeys gelangen möchte, die immer zurückgeliefert werden. Es
kommt immer wieder vor, dass (vermutlich aus Bequemlichkeit oder Unwissenheit) ein
Statement der Form select * where myProperty = 'XXX'
abgesetzt wird, obwohl z.B. nur der Anzeigename und die Objektklasse benötigt werden. Richtig
wäre in diesem Fall folgendes Statement:
select displayname, objectclass where myProperty = 'XXX'
Falls wie erwähnt gar kein Attribut benötigt wird, muss das Statement so formuliert werden:
where myProperty = 'XXX'
NQL verlangt keine Select-Klausel, sie ist optional und kann weggelassen werden. Es muss einem
klar sein, dass ein select * die maximale Belastung für den Server darstellt, da über alle
Stammdaten- und Multivalue-Tabellen gejoint werden muss und zusätzlich alle berechneten
Attribute (ComputedProperties und FormattedProperties) berechnet werden müssen. Das ist besonders
ärgerlich, wenn diese Attribute gar nicht benötigt werden.
7.3.2. SearchControl statt NQL
Die Suchparameter können im Server auf zwei Arten dargestellt werden: als SearchControl oder als NQL (nscale Query Language). Wenn es auf Geschwindigkeit ankommt, ist die Benutzung des SearchControls vorzuziehen, da NQL im Server geparst werden muss und in ein SearchControl konvertiert wird. Diese Zeit kann gespart werden, wenn schon der Client das SearchControl benutzt.
Achtung: Natürlich bringt es auch nichts, im SearchControl eine StringCondition bzw. StringQueryOperands zu benutzen, da diese ebenfalls geparst werden müssen.
7.3.3. Paging
Es sollte mit Paging gearbeitet werden, um auszuschließen, dass das ResultSet zu groß wird.
Ebenso sollte der SearchScope passend gesetzt werden. Wenn nur überprüft werden soll, ob eine
Bedingung für mindestens eine Ressource zutrifft, kann Paging mit den Werten (0, 1) aufgerufen
werden (erste Seite, null Treffer). Das Vorhandensein einer Ressource kann einfach durch
Abfragen des Flags hasMore im ResultSet ermittelt werden.
Wenn nur die Gesamtzahl der Treffer ermittelt werden soll, kann eine Aggregatsuche
select count(identifier)
oder alternativ eine count-Suche abgesetzt werden, hier ein Beispiel für NQL:
paging (size=0, number=1) count
Letztere Suche liefert ein leeres ResultSet zurück, aber die Anzahl der Treffer ist im ResultSet
vermerkt.
Achtung: ein select count(*) auf der Datenbank ist sehr teuer, die Gesamtanzahl sollte nur
abgefragt werden, wenn sie wirklich benötigt wird.
Im DbSetting gibt es die Einstellung, ob eindeutiges Paging benutzt werden soll. Ist diese
Einstellung aktiv, wird bei jeder Suche mit Paging eine order-by-Klausel hinzugefügt, die die
Performance negativ beeinträchtigen kann. Der Vorteil bei aktivierter Einstellung ist, dass die
Reihenfolge der Einträge aller Seiten eindeutig ist und es somit nicht zu duplizierten oder
fehlenden Einträgen in verschiedenen Seiten kommen kann. Um nicht unnötig Performance zu verlieren
wird empfohlen, diese Einstellung zu deaktivieren und statt dessen nur bei Suchen mit Paging, die
tatsächlich mehrere Seiten abrufen und nicht sowieso eine eindeutige Sortierung festlegen,
eine Sortierung nach einem Schlüsselattribut anzuhängen, z.B. order by identifier im Bereich Repository.
|
7.3.4. Optimierung der Where-Klausel
Die Where-Bedingung sollte optimiert werden. Wenn es möglich ist, sollte die Benutzung von OR-Klauseln
vermieden werden. In der Regel kann eine AND-Klausel durch die Datenbank schneller
und effizienter geparst werden. Falls eine OR-Verknüpfung für ein Attribut mehrere verschiedene
Werte abfragt, sollte stattdessen eine IN-Klausel verwendet werden, z.B. sollte statt
x = 1 or x = 2 or x = 3 das Statement x in (1, 2, 3) benutzt werden.
Ebenso sollte nach Möglichkeit eine Abfrage auf is null bzw. is not null vermieden werden.
Beispiel: Um noch nicht beendete Tasks im Workflow abzufragen, gibt es mehrere Möglichkeiten.
Folgende Bedingung ist teuer: where taskenddate is null
Folgende Bedingung ist billig: where not taskended
Um zu verhindern, dass Attribute potentiell null enthalten (und so ggf. eine Abfrage auf null
erfordern), können Attributen auch Default-Werte gegeben werden. Diese können bei Bedarf auch
nachträglich automatisch gesetzt werden, z.B. bequem im nscale Administrator.
Oft ist es möglich, eine ineffiziente Abfrage durch Umformulierung in eine äquivalente performante Abfrage zu verändern. Wenn ein Attribut oder eine Kombination von Attributen in der Where- oder OrderBy-Bedingung benutzt wird, sollte überlegt werden, ob es sinnvoll ist, einen passenden DB-Index anzulegen (dies wird auch bequem im nscale Administrator angeboten).
7.3.5. Auswertung des ResultSets
Beim Iterieren des ResultSets einer Suche sollte mit Indizes gearbeitet werden, z.B. hat die
Methode getCell( int columnIndex, int rowIndex) konstanten Aufwand, während die
Methode getCell ( PropertyName propertyName, ResourceKey resourceKey ) erst die
passenden Einträge im ResultSet suchen muss und daher Zeit verbraucht. Analog gilt das auch
für die Methoden getRow(…) und getColumn(…).
7.4. Custom Computed Properties im Batch
Erstellt man ein Plugin für Custom Computed Properties, das die Default-Implementierung DefaultCustomComputedIndexingPropertyDefinitionsHandler
erweitert, können für die Berechnung zwei Methoden überschrieben werden, die Methoden compute und batchCompute.
Wenn Zwischenergebnisse von Berechnungen wiederverwendet werden können, sollte die Methode batchCompute überschrieben werden,
da dies eine deutliche Performance-Steigerung bewirken kann. Beispiel: es soll eine Property erzeugt werden, die den Anzeigenamen des
Eltern-Ordners zurückgibt. Eine Implementierung von compute könnte so aussehen: ![]()
public Object compute ( IndexingPropertyName name,
PluginExecutionContext executionContext,
Object... necessaryValues ) {
Object ret = null;
if ( name.getName().equals ( "parentdisplayname" ) ) {
String parentResourceId = ( String ) necessaryValues [ 0 ];
String dn = null;
if ( parentResourceId != null ) {
ResourceKey key = new ResourceKey ( parentResourceId );
IndexingPropertyName ipn = new IndexingPropertyName ( "displayname",
name.getAreaName() );
dn = executionContext.getRepositoryService()
.getProperties ( key, Arrays.asList ( ipn ) )
.get ( 0 )
.value();
}
ret = dn;
} else {
// delegate to batchCompute
Object[][] nvs = new Object [ 1 ][ necessaryValues.length ];
nvs [ 0 ] = necessaryValues;
ret = batchCompute ( name, executionContext, nvs ) [ 0 ];
}
return ret;
}Diese Implemtierung kann sehr inperformant sein, da für viele Ressourcen immer wieder der gleiche Anzeigename neu berechnet wird
(für alle, die den gleichen Eltern-Ordner haben).
Die Implementierung kann verbessert werden, wenn die Methode batchCompute benutzt wird: ![]()
public Object[] batchCompute ( IndexingPropertyName name,
PluginExecutionContext executionContext,
Object[][] necessaryValues ) {
Object[] ret = new Object [ necessaryValues.length ];
if ( name.getName().equals ( "parentdisplayname" ) ) {
Map < String, String > dns = new HashMap<>();
IndexingPropertyName ipn = new IndexingPropertyName ( "displayname",
name.getAreaName() );
List < IndexingPropertyName > ipns = Arrays.asList ( ipn );
for ( int i = 0; i < ret.length; i++ ) {
String parentResourceId = ( String ) necessaryValues [ i ][ 0 ];
if ( !dns.containsKey ( parentResourceId ) ) {
String dn = null;
if ( parentResourceId != null ) {
ResourceKey key = new ResourceKey ( parentResourceId );
dn = executionContext.getRepositoryService()
.getProperties ( key, ipns )
.get ( 0 )
.value();
}
dns.put ( parentResourceId, dn );
ret [ i ] = dn;
} else {
ret [ i ] = dns.get ( parentResourceId );
}
}
} else {
// delegate to super-class
ret = super.batchCompute ( name, executionContext, necessaryValues );
}
return ret;
}8. Methodenaufrufe im System-Kontext
Es sollte einem bewusst sein, dass Aufrufe von Service-Methoden innerhalb von Plugins im System-Kontext aufgerufen werden. Diese Tatsache hat mehrere Konsequenzen. Zum einen werden im System-Kontext keine Rechte ausgewertet, d.h. im System-Kontext sind Methodenaufrufe erlaubt, die dem initialen Benutzer (der, dessen Service-Request im Plugin abgefangen wurde) evtl. nicht besitzt. Insbesondere gibt es auch keine Einschränkungen bei Suchen, d.h. eine Suche im System-Kontext findet alle Ressourcen.
Eine weitere Konsequenz ist, dass Attribute, die mit der Principal-Id des aktuellen Benutzers gefüllt werden, im System-Kontext
auch durch die Id des System-Benutzers gefüllt werden, z.B. wird bei Erstellung einer Version eines Dokuments als Ersteller
der System-Benutzer eingetragen (betrifft Systemattribut creator) und nicht die Id des Benutzers, der initial den
Service-Request ausgelöst hat.
Um in Plugins die Suche im Kontext eines Benutzers zu simulieren, bietet der Server seit Version 7.8 im CommonRuntimeService
(Oberklasse der Runtime-Services wie z.B. PluginRuntimeService) die Methode getPrincipalCondition(…) an, die eine Condition
zurückliefert, die die Sichtbarkeit des als Parameter übergebenen Benutzers repräsentiert. Wenn diese Condition im Filter einer Suche
benutzt wird, findet die Suche nur die Treffer, die auch der Benutzer finden würde. Achtung: hierarchische Berechtigungen werden in der
zurückgelieferten Condition nicht berücksichtigt.
|
8.1. Benutzung des initialen Kontexts
Ab Version 7.13 bietet der nscale Server Application Layer im CommonRuntimeService die Methode setUseInitialContext(boolean)
an. Wenn der Wert auf true gesetzt wird, finden alle nachfolgenden Methoden-Aufrufe innerhalb des Plugins im Kontext des Benutzers statt,
der initial den Service-Request abgesetzt hat (z.B. im Cockpit-Client). Wird der Wert wieder auf false gesetzt, geschehen nachfolgende
Methoden-Aufrufe wieder im System-Kontext. Das Setzen des initialen Kontexts ist nicht rekursiv, d.h. wenn ein Methoden-Aufruf im
initialen Kontext wiederum von einem Plugin abgefangen wird und in diesem Plugin weitere Methoden aufgerufen werden, werden diese Methoden
wieder im System-Kontext ausgeführt. Anders ausgedrückt: jedes Plugin ist selber dafür verantwortlich, den initialen Kontext zu setzen, das
Plugin erbt das Setzen des initialen Kontexts nicht von der aufrufenden Methode.
Ab Version 7.15 steht im CommonRuntimeService zusätzlich die Methode isInitialContextSet() zur Verfügung. Mit Hilfe dieser Methode
kann innerhalb eines Plugins abgefragt werden, ob für den aktuellen Methodenaufruf der initiale Kontext gesetzt wurde, d.h. ob vor dem Aufruf
der Methode innerhalb eines Plugins die Methode setUseInitialContext(true) aufgerufen wurde.
9. Plugin-Typ CustomJob (Aufgaben)
Beim Hochladen eines Plugins vom Typ CustomJob wird automatisch auch eine zugehörige Aufgabe erstellt. Sowohl Plugin als auch Aufgabe können getrennt voneinander aktiviert bzw. deaktiviert werden. Hierbei gelten folgende Regeln:
-
Plugin aktiviert, Aufgabe aktiviert:
Das Plugin wird von der Aufgabe gemäß der Aufgabenkonfiguration ausgeführt. -
Plugin aktiviert, Aufgabe deaktiviert:
Die Aufgabe und damit das Plugin werden nicht ausgeführt. Die InitialisierungsmethodenafterConfiguredunddestroydes Plugins werden allerdings ausgeführt. -
Plugin deaktiviert, Aufgabe aktiviert:
Die Aufgabe wird zwar aufgerufen, führt aber dieexecute-Methode des Plugins nicht aus. Es wird eine Warnung protokolliert. Die Initialisierungsmethoden werden ebenfalls nicht ausgeführt. -
Plugin deaktiviert, Aufgabe deaktiviert:
Weder Aufgabe noch Plugin werden ausgeführt.
9.1. Plugins und CustomJobs im nscale Cluster
Unter nscale Cluster wird der Clusterverbund mehrerer nscale Server Application Layer verstanden, die auf Basis eines zentralen, gemeinsamen Datenbank Schemas konfiguriert sind oder anders ausgedrückt: alle nscale Server Application Layer, die auf die gleiche Datenbank bzw. das gleiche Schema zugreifen, bilden einen Clusterverbund.
9.1.1. CustomJobs
Je nach Typ (Core Job, Single Job, Multiple Job) des CustomJobs wird dieser auf allen Clusterknoten oder
differenziert auf nur einem oder mehreren Clusterknoten ausgeführt. Dies kann individuell über die
jeweilige Instanzkonfigurationsdatei (z.B. instance1.conf) bzw. bequemer über die Instanzkonfiguration im
nscale Administrator (die auf die selbe Datei zugreift) eingestellt werden. Vgl. auch die Beschreibung der Parameter
cluster.core.job.coordinator.jobNames=… und cluster.core.job.coordinator.excludedJobNames=…
in der Instanzkonfigurationsdatei.
9.1.2. Plugins
Sofern nicht anders konfiguriert, ist ein Plugin zunächst auf allen Knoten verfügbar bzw.
kann von jedem Knoten „getriggert“ werden.
Es gibt keinen vergleichbaren Mechanismus wie bei den CustomJobs, um individuell einstellen zu
können, auf welchen Knoten ein Plugin getriggert wird und wo nicht. Als Behelf lässt sich die
Ausführung eines Plugins explizit für einen Knoten ausschließen, indem für den Clusterknoten das
Plugin explizit über den Bypass Mechanismus deaktiviert wird (Parameter core.plugin.bypass.plugins=…
in der Instanzkonfigurationsdatei). Alternativ kann natürlich auch innerhalb des Plugin-Codes der
Name des aktuellen Clusterknotens abgefragt werden und entsprechend der Code ausgeführt werden oder nicht.
9.2. Vermeidung von lost-updates in CustomJobs
Das Scheduling eines CustomJobs entscheidet darüber, wann der Job automatisch ausgeführt wird. Es sollte beim Scheduling darauf geachtet werden, dass die Ausführung des Jobs möglichst zu einem Zeitpunkt stattfindet, an dem keine weiteren Aktionen auf dem gleichen Datenbestand stattfinden, die auch der Job bearbeitet, sei es durch Aktionen von Benutzern oder durch andere Jobs. Natürlich gilt das auch für den Fall, wenn ein Job manuell angestoßen wird.
Selbstverständlich ist es nicht immer vorher möglich zu entscheiden, ob zu einem Zeitpunkt gleichzeitige schreibende Zugriffe auf die gleiche Ressource (z.B. ein Dokument) stattfinden. Falls das passiert, wird es unweigerlich zu lost-updates kommen, d.h. eine Transaktion überschreibt die Änderungen einer anderen Transaktion. Um dieses Szenario möglichst zu vermeiden, sollten gewisse Strategien im CustomJob beachtet werden.
Bevor schreibend auf eine Ressource im CustomJob zugegriffen wird, sollte ein exklusiver Zugriff auf die
Ressource gewährleistet sein. Das geschieht durch Setzen einer Sperre auf die betroffene Ressource. Die hier relevanten
Services RepositoryService, WorkflowService und BusinessProcessService bieten zu diesem Zweck die Methoden
lock zum Sperren und unlock zum Entsperren an.
Wenn Methode lock auf einer Ressource aufgerufen wird und erfolgreich durchläuft, kann man sicher sein,
dass ein exklusiver Zugriff gewährleistet ist. Potentiell parallele Aufrufe der lock-Methode auf einer Ressource
führen dazu, dass nur einer der Aufrufe erfolgreich durchläuft, alle anderen erhalten eine ResourceLockedException.
Solange der Job läuft und nicht Methode unlock aufruft, bleibt die Ressource gesperrt. Ein administrativer Versuch,
die Sperre zu brechen, würde mit einer Exception zurückgewiesen, solange der Job noch läuft.
Wenn eine Sperre erfolgreich gesetzt wurde, kann die Ressource bedenkenlos bearbeitet werden. Versuche von anderen
Clients oder Jobs, die Ressource ebenfalls zu bearbeiten, würde der Server mit einer ResourceLockedException
beantworten. Am Ende der Bearbeitung sollte die Ressource durch Aufruf der unlock-Methode wieder entsperrt werden.
Es bietet sich hier an, die Bearbeitung in einem try-Block durchzuführen und den unlock-Aufruf
im finally-Block abzusetzen.
Der Server bietet diverse Properties an, die Informationen zur Sperre einer Ressource enthalten. Im Bereich Repository
z.B. werden die Properties lockowner, lockownername, lockownercommonname, lockdate und
lockcontext angeboten. In den Bereichen Workflow und BusinessProcess werden analoge Properties angeboten.
Die ersten drei Properties enthalten Informationen zu dem Benutzer, der eine Sperre gesetzt
hat, während die vierte Property das Datum der Sperrung enthält. Die fünfte Property ist neu in nscale Version 9
hinzugekommen, sie enthält den Kontext der Sperre. Der Kontext wird gesetzt, wenn eine Sperre in einem Job gesetzt wird
(gilt auch für System-Jobs), die Property enthält dann den Namen des sperrenden Jobs. Da eine Sperre in Jobs
(und auch in Plugins) immer durch Benutzer System gesetzt wird, musste ein Kriterium geschaffen werden, um den Kontext
der Sperre zu erkennen. ActionHandler, wie sie z.B. vom WorkflowSchedulerJob ausgeführt werden, setzen keinen Kontext.
Es bietet sich an, dass ein CustomJob vor dem Setzen einer Sperre immer erst mindestens die
Properties lockowner und lockcontext abfragt, um erkennen zu können, ob die Ressource bereits in einem anderen
Kontext gesperrt wurde. Ist das der Fall, sollte der Job die Ressource vorläufig unberührt lassen.
Prinzipiell kann ein Job einen Lock mit dem Kontext eines anderen Jobs durch einen unlock-Aufruf brechen,
sofern dieser andere Job gerade nicht läuft. Dieses sollte allerdings nur sehr selten gemacht werden, z.B. wenn
ein Lock bereits sehr lange gesetzt ist und zu befürchten ist, dass die Ressource sonst nie wieder entsperrt werden würde.
Beispiel-Code:
boolean locked = false;
try {
String areaName = ResourceKeyInfo.get ( key ).getDocumentAreaName();
List < PropertyName > pNms =
pExecCtx.getJobRuntimeService()
.buildPropertyNames ( SearchContext.REPOSITORY ( areaName ),
PropertyNameConstants.PROPERTYNAME_LOCKOWNER,
PropertyNameConstants.PROPERTYNAME_LOCKCONTEXT );
List < Property > ps = pExecCtx.getRepositoryService().getProperties ( key, pNms );
String lockOwner = ps.get ( 0 ).value();
String lockContext = ps.get ( 1 ).value();
boolean proceed = lockOwner == null
|| lockOwner.equals ( PrincipalEntity.SYSTEM_PRINCIPAL_ID )
&& lockContext.equals ( pExecCtx.getJobRuntimeService()
.getJobName() );
if ( proceed ) {
pExecCtx.getRepositoryService().lock ( key );
locked = true;
// proceed...
}
} catch ( ResourceLockedException exc ) {
logger.warn ( "Resource " + key + " is locked." );
} finally {
if ( locked ) {
pExecCtx.getRepositoryService().unlock ( key );
}
}
Selbst wenn eine selbst erstellte Klasse nicht wie hier vorgeschlagen angepasst wird, muss einem bewusst sein, dass durch den vermehrten
Einsatz von Sperren, sich das Verhalten ändern könnte. System-Jobs setzen vor der Verarbeitung einer Ressource jetzt immer eine Sperre, und wenn
auch Custom-Jobs wie beschrieben erweitert werden, kann es vorkommen, dass Code, der bisher durchlief, jetzt auf eine ResourceLockedException läuft.
Es sollte überprüft werden, ob mindestens das Error-Handling entsprechend angepasst werden sollte.
|
9.2.1. Vorgehen bei Single-Tx CustomJobs
Für den Fall, dass ein CustomJob erstellt wird, der in einer einzigen Transaktion arbeitet, muss anders vorgegangen werden.
Der Lock muss in diesem Fall innerhalb einer TransactionCallback-Klasse stattfinden. Der Server liefert zu diesem
Zweck die Klasse LockResourceCallback mit aus, die dafür benutzt werden kann:
LockResourceCallback lrc = new LockResourceCallback ( key, pExecCtx.getRepositoryService() );
locked = pExecCtx.getJobRuntimeService().execute ( lrc );Für den korrekten Umgang mit TransactionCallback siehe Benutzerdefinierte Transaktionen.
10. Client-Code im Server
Gelegentlich kommt der Wunsch auf, Client-Code im Server ausführen lassen zu können. Dies wird nicht unterstützt, jedoch gibt es eine Möglichkeit, die Anforderung annähernd
umzusetzen. Es gibt im MonitoringService die generische Methode invokeGenericMonitoringMethod, die im Server keine Auswirkung hat und nur dazu gedacht
ist, in Plugins (sprich in ServiceInvocationHooks) abgefangen zu werden, um dort benutzerdefinierten Code auszuführen.
Angenommen, ein Client möchte eine Funktionalität entwickeln, bei der eine Ressource kopiert und die Original-Ressource anschließend logisch gelöscht werden soll, so kann er den Code in einen ServiceInvocationHook folgendermaßen auslagern:
public Object afterReturning ( Object returnValue,
Method method,
Object[] args,
PluginExecutionContext pExecCtx ) {
if ( method.getName().equals ( MonitoringMethodKey.invokeGenericMonitoringMethod.name() ) ) {
String methodName = ( String ) args [ 0 ];
if ( "copyAndDelete".equals ( methodName ) ) {
Object[] parameters = ( Object[] ) args [ 1 ];
ResourceKey source = ( ResourceKey ) parameters [ 0 ];
ResourceKey target = ( ResourceKey ) parameters [ 1 ];
returnValue = pExecCtx.getRepositoryService().copy ( source, target );
pExecCtx.getRepositoryService().deleteLogical ( source );
}
}
return returnValue;
}Der Aufruf im Client könnte so aussehen:
newKey = ( ResourceKey ) monitoringService.invokeGenericMonitoringMethod ( "copyAndDelete",
sourceKey,
targetKey );10.1. Service-Adapter
Die .NET AdvancedConnector Schnittstelle bietet einen Service-Adapter an, um bequemer diese Möglichkeit nutzen zu können. Der Service-Adapter ermöglicht es, ein Interface
zu definieren, für das die Schnittstelle eine Proxy-Implementierung erstellt, das auf die generische Methode invokeGenericMonitoringMethod delegiert. Das Interface
muss das zur Verfügung gestellte Interface IAdapter erweitern. Hinweis: in der Core-Variante des .NET AdvancedConnectors steht dieser Adapter nicht zur Verfügung.
Beispiel:
public interface MyAdapter : IAdapter
{
String Foo ();
void Bar ( String s );
ResourceKey CopyAndDelete ( ResourceKey source, ResourceKey target );
}Anwendung im Client:
void TestMyAdapter ( ISession session )
{
MyAdapter myAdapter = AdapterInstance.Get < MyAdapter > ( session );
String s = myAdapter.Foo();
myAdapter.Bar ( s );
//...
myAdapter.Dispose();
}
Um die Namenskonventionen von Java und C# zu berücksichtigen, wird dem Server der Methodenname mit kleingeschriebenem erstem Buchstaben übergeben, im obigen Beispiel also foo bzw. bar.
|
10.2. Asynchrone Ausführung
Funktionalitäten, die mittels der Methode invokeGenericMonitoringMethod aufgerufen werden, können auch asynchron ausgeführt werden. Der Server liefert dazu seit Version 7.12
die Klasse com.ceyoniq.nscale.al.core.plugin.hook.AsynchronousMethodExecutor aus. Instanziiert man einen ServiceInvocationHook, der diese Klasse benutzt, dann werden
alle Aufrufe von invokeGenericMonitoringMethod, dessen Methoden-Name den Präfix async oder async_ hat, asynchron ausgeführt. Im obigen Beispiel reicht also ein Aufruf der Form:
monitoringService.invokeGenericMonitoringMethod ( "async_copyAndDelete", sourceKey, targetKey );Eine Methode, die asynchron ausgeführt wird, hat als Rückgabewert natürlich immer den Wert null.
11. Reihenfolge der Abarbeitung
In diesem Kapitel werden Informationen zur Abarbeitungsreihenfolge der verschiedenen Arten von Plugins gegeben, sowohl während der Initialisierung als auch während des laufenden Betriebs.
11.1. Hierarchie der Plugin-Interfaces und deren Methoden
Die folgende Abbildung gibt einen Überblick über die am häufigsten benutzten Plugin-Arten. Es werden die von den Plugins zu implementierenden Interfaces (Handler der Plugins) und deren Methoden dargestellt.
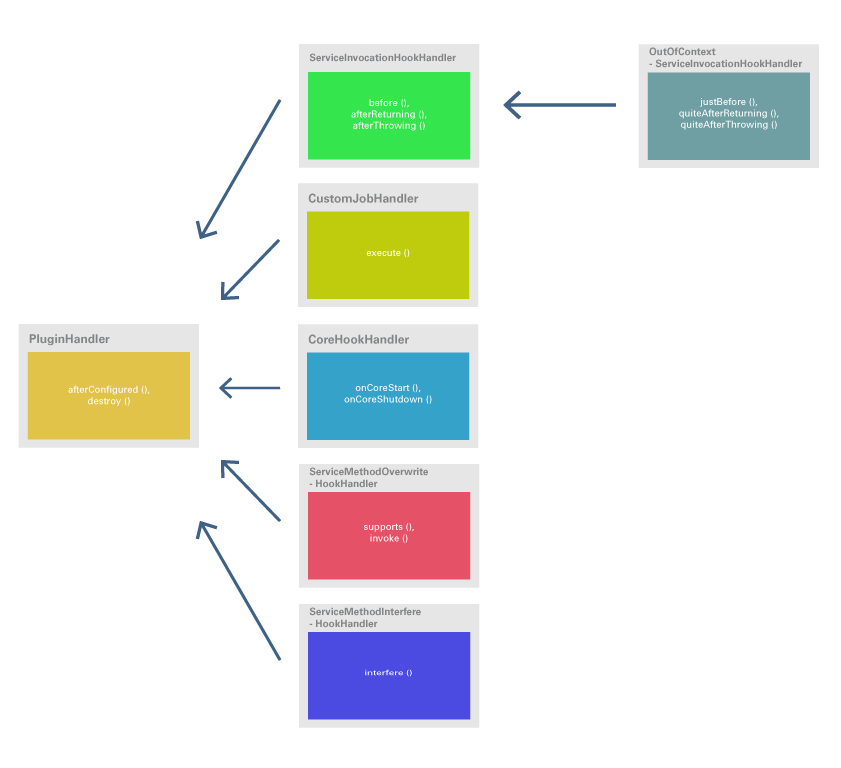
| Für jeden Plugin-Handler liefert der nscale Server Application Layer eine Default-Implementierung aus. Als Name dieser Klassen wird der Name des jeweiligen Handler-Interfaces benutzt, wobei jeweils als Präfix Default gesetzt wird, also z.B. DefaultServiceInvocationHookHandler für das Interface ServiceInvocationHookHandler. Es wird empfohlen, bei der Plugin-Entwicklung die Default-Implementierung zu erweitern statt das Interface direkt zu implementieren. |
11.2. Aufruf-Reihenfolge
Beim Start des nscale Server Application Layers (bzw. Reinitialisierung der Plugins) werden die Initialisierungsmethoden afterConfigured()
und afterConfigured(PluginExecutionContext) (falls das Plugin das Interface ContextAwarePluginHandler implementiert) eines jeden Plugins aufgerufen.
Die Reihenfolge ist fest definiert (siehe Abbildung unten). Wird der Application Layer heruntergefahren (bzw. bei Zerstörung der alten Plugins vor der Reinitialisierung),
werden analog die Methoden destroy() und destroy(PluginExecutionContext) (falls das Plugin das Interface DestroyableContextAwarePluginHandler
implementiert) aufgerufen.
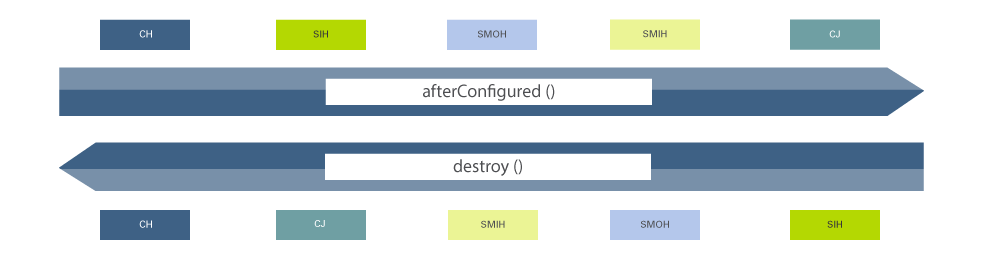
Legende der häufigsten Plugin-Arten:
Nachfolgend sieht man die Reihenfolge der Abarbeitung unterschiedlicher Plugins bei Aufruf einer
Service-Methode (z.B. createDocument(…)).
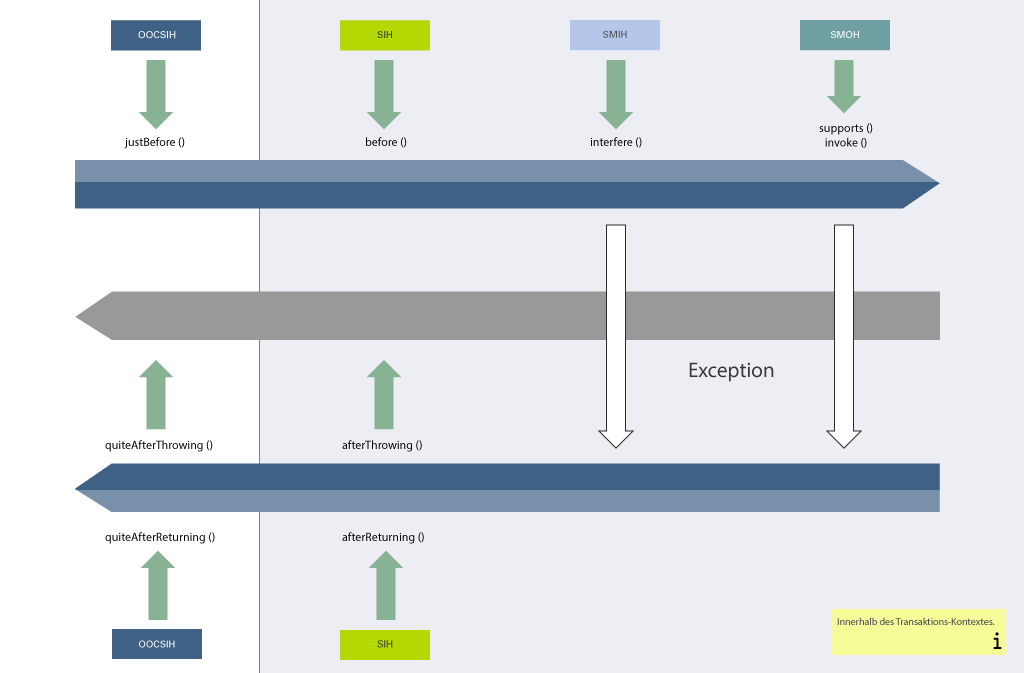
12. Best Practice
Abschließend noch einige kurze Beispiele für ein empfohlenes Vorgehen.
12.1. Aufruf eines Hooks durch einen anderen
Siehe Endlosschleifen
12.2. Vermeidung von Blocking-Lock-Situationen
Als goldene Regel kann man sagen, dass zwischen einer schreibenden Operation der äußeren und einer schreibenden Operation der inneren Transaktion KEIN Lesevorgang auf demselben Datenbestand stattfinden darf und nach Möglichkeit alle lesenden Zugriffe vor den schreibenden stattfinden sollten.
12.3. Native Libs
Die Plugin-Factory von nscale Server Application Layer kopiert alle in Plugins enthaltenen externen
Bibliotheken (engl. Libraries, *.dll-Dateien unter Windows, *.so-Dateien unter Unix) in das native lib
-Verzeichnis. Es hat sich gezeigt, dass es im Umgang mit DLLs und dem Nachladen von Klassen zur
Laufzeit oftmals zu Schwierigkeiten kommt. Im Zweifelsfall sollte auf eine der unten beschriebenen
Alternativen ausgewichen werden.
12.4. Umgang mit Klassen und Jar-Dateien
Nach Möglichkeit sollten einzelne Java *.class Dateien erst in eine *.jar Datei gepackt und dann mit
nscale Administrator hochgeladen werden. Aufgrund der internen geschachtelten Classloader Logik ist
dieses Vorgehen sehr viel performanter.
Hintergrund:
Wenn viele einzelne Java *.class Dateien existieren, müssen diese alle explizit mittels nscale
Classloader nscale Server Application Layer bekannt gemacht werden. Je mehr Dateien existieren,
umso länger dauert der Vorgang.
12.5. Alternative bis Version 7.2
Werden sehr viele zusätzliche Klassen und Pakete benötigt, so können diese über einen anderen Weg
nscale Server Application Layer dauerhaft bekannt gemacht werden. Hierzu besteht die Möglichkeit,
den java.classpath Parameter in der service.conf Datei zu erweitern. Dies hat zur Konsequenz,
dass über diesen Weg hinzugefügte Klassen und jar-Dateien sofort zur Verfügung stehen und vor allem
nicht bei jeder PluginsSetting Änderung immer wieder (s.o.) nachgeladen werden müssen.
Aber:
Beachten Sie, dass manuelle Änderungen am java.classpath Parameter beim Upgrade-Prozess nicht
berücksichtigt werden. Beim Upgrade-Prozess werden manuelle Änderungen überschrieben und die
Änderung muss anschließend erneut durchgeführt werden. Zudem ist zu beachten, dass auf diesem
Wege hinzugefügte Klassen und Packages nur auf diesem Knoten verfügbar sind. Beim Clusterbetrieb
bzw. im Zweifelsfall ist diese manuelle Erweiterung für jeden(!) Knoten durchzuführen!
Aus diesem Grund ist dieses nicht der empfohlene Weg, obwohl er unter bestimmten Umständen sinnvoll sein kann.
12.6. Alternative ab Version 7.3
nscale Server Application-Layer nimmt alle Bibliotheken, die im Verzeichnis <InstallDir>/lib/ext
liegen, mit in den Standard-Anwendungs-Classloader auf. Damit entfällt das Anpassen der java.classpath
Einstellung in der Datei service.conf.
Dieses Vorgehen soll nicht den Standard-Plugin-Mechanismus ersetzen. Allerdings hat es sich gezeigt, dass es mit dem Plugin-Classloader Probleme geben kann:
-
Laden von nativen Bibliotheken (Abstürze können insbesondere unter Unix geschehen, wenn die Bibliotheken z.B. durch ein Update der Konfiguration ein weiteres mal geladen werden.)
-
Laden von Ressourcen innerhalb von jar-Dateien.
-
Beim Abstieg in den System-Classloader werden Plugin-Klassen oder jar-Dateien nicht gefunden.
13. FAQ
-
Wenn ich einen Fehlerstatus setze, wird dieser beim Zurückrollen der Transaktion auch immer wieder zurückgesetzt - wie kann ich das verhindern?
Antwort: siehe Error Handling -
Gibt es Beispiele zu den hier beschriebenen Verfahren und Techniken?
Antwort: Ja, diverse Java-Beispielklassen befinden sich im nscale SDK. -
Wie verhindere ich, dass mein Plugin eine Endlosschleife erzeugt?
Antwort: Um zu verhindern, dass ein Plugin durch seine Implementierung wiederum selbst aufgerufen wird, kann man über den ThreadLocal-Mechanismus den ersten Aufruf signalisieren und damit einen erneuten Aufruf verhindern. Siehe auch Stichwort Endlosschleifen. -
Nach Einspielen meiner Plugins bekomme ich vermehrt Lock- bzw. DeadLock-Situationen auf der Datenbank. Was kann ich tun?
Antwort: Nach unserer Erfahrung treten gerade Blocking-Lock-Situationen in Verbindung mit TransactionCallBack-Aufrufen auf. Unter Deadlocks / Blocking Locks beschreiben wir Designempfehlungen, um die Wahrscheinlichkeit für Blocking Locks zu minimieren. -
Die maximale Länge der Parameterwerte für Plugins scheint begrenzt zu sein, kann ich die maximale Länge vergrößern?
Antwort: Ja richtig, die maximale Länge aller Parameterwerte inkl. der impliziten XML Struktur beträgt 4000 Zeichen. Wird ein größerer Wert benötigt, empfehlen wir, mit einer klassischen Properties-Datei zu arbeiten. Diese Datei, z.B.MyParameters.properties, wird einfach zusammen mit dem Plugin-Code im Server hochgeladen und kann dann zur Laufzeit entsprechend ausgelesen werden, z.B. über die MethodegetResourceAsStream(…)des ClassLoaders.